
Basic-推荐系统链路
本博文引自王树森老师推荐系统。
视频地址:概要02:推荐系统的链路_哔哩哔哩_bilibili
课件地址: https://github.com/wangshusen/RecommenderSystem
推荐系统链路
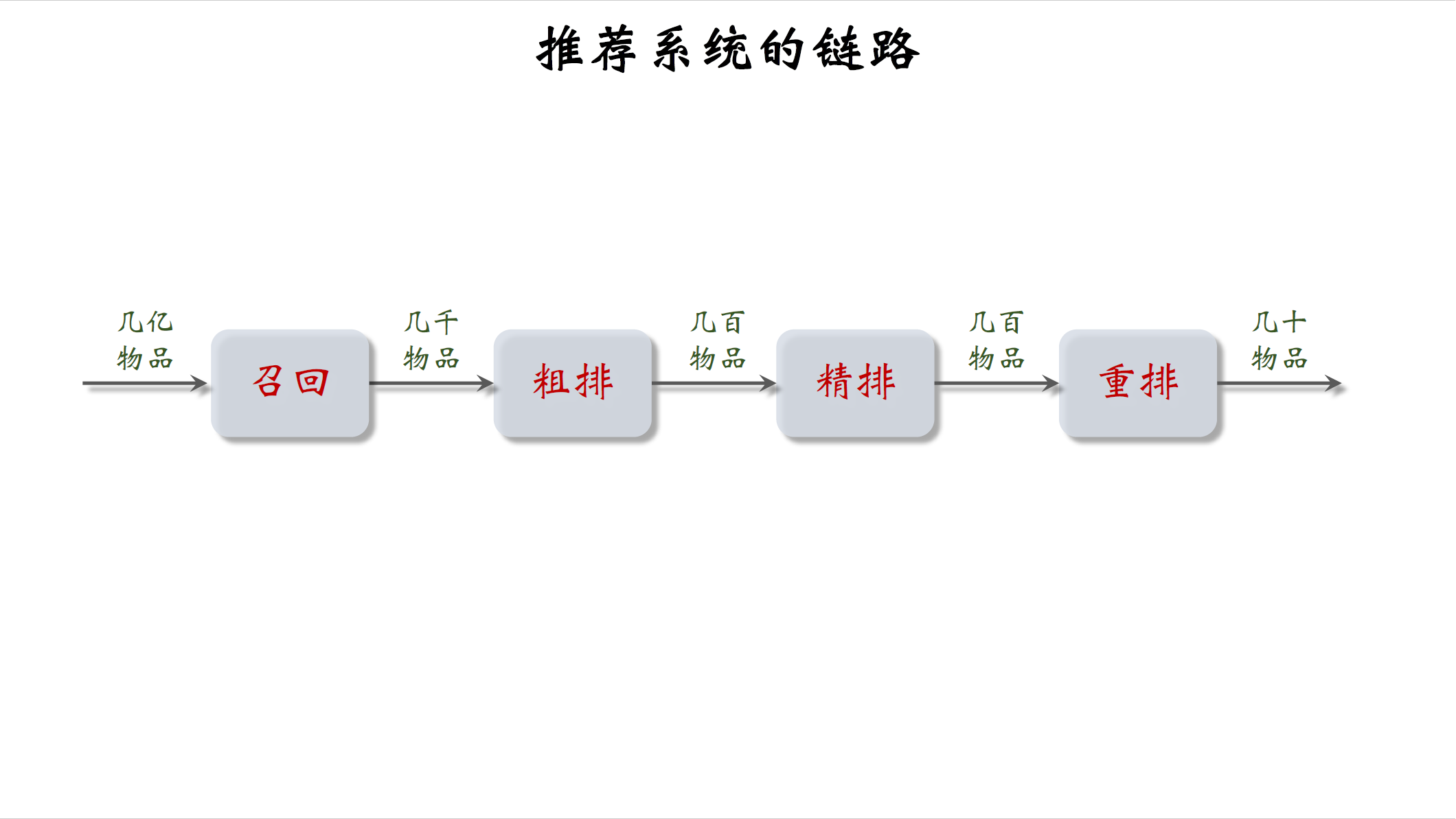
第一步是召回,从物品的数据库中快速取回一些物品。比如小红书有几亿篇笔记,用户刷新小红书时,会调用几十条召回通道,每条召回通道选出几十到几百篇笔记,一共取回几千篇笔记。召回之后,要从几千篇笔记中选出用户最感兴趣的笔记。
下一步是粗排,用规模较小的机器学习模型给几千篇笔记逐一打分,按照分数做排序和截断,保留分数最高的几百篇笔记。
再下一步是精排,这里要用大规模的神经网络给几百篇笔记逐一打分,精排的分数反映出用户对笔记的兴趣,在精排之后可以做截断也可以不做,小红书不做截断,所有几百篇笔记都带着分数进入重排。
重排是最后一步,这里会根据精排分数和多样性分数做随机抽样,最后得到几十篇笔记,然后把相似内容打散,并且插入广告和运营内容。
召回
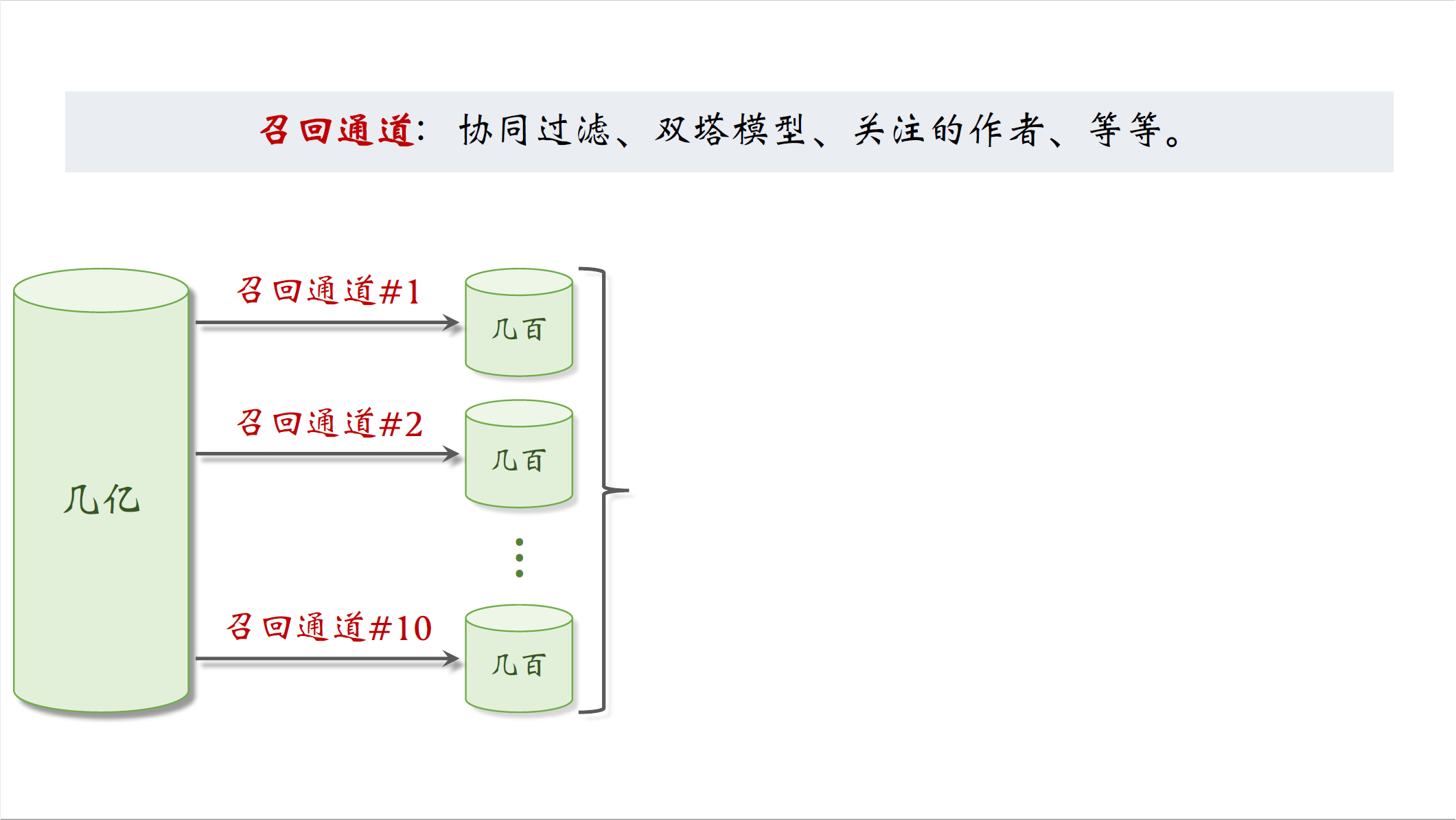
这些召回通道会返回几千篇笔记,然后推荐系统会融合这些笔记,做去重和过滤(过滤是指排除掉用户不喜欢的作者,笔记,话题)。
排序
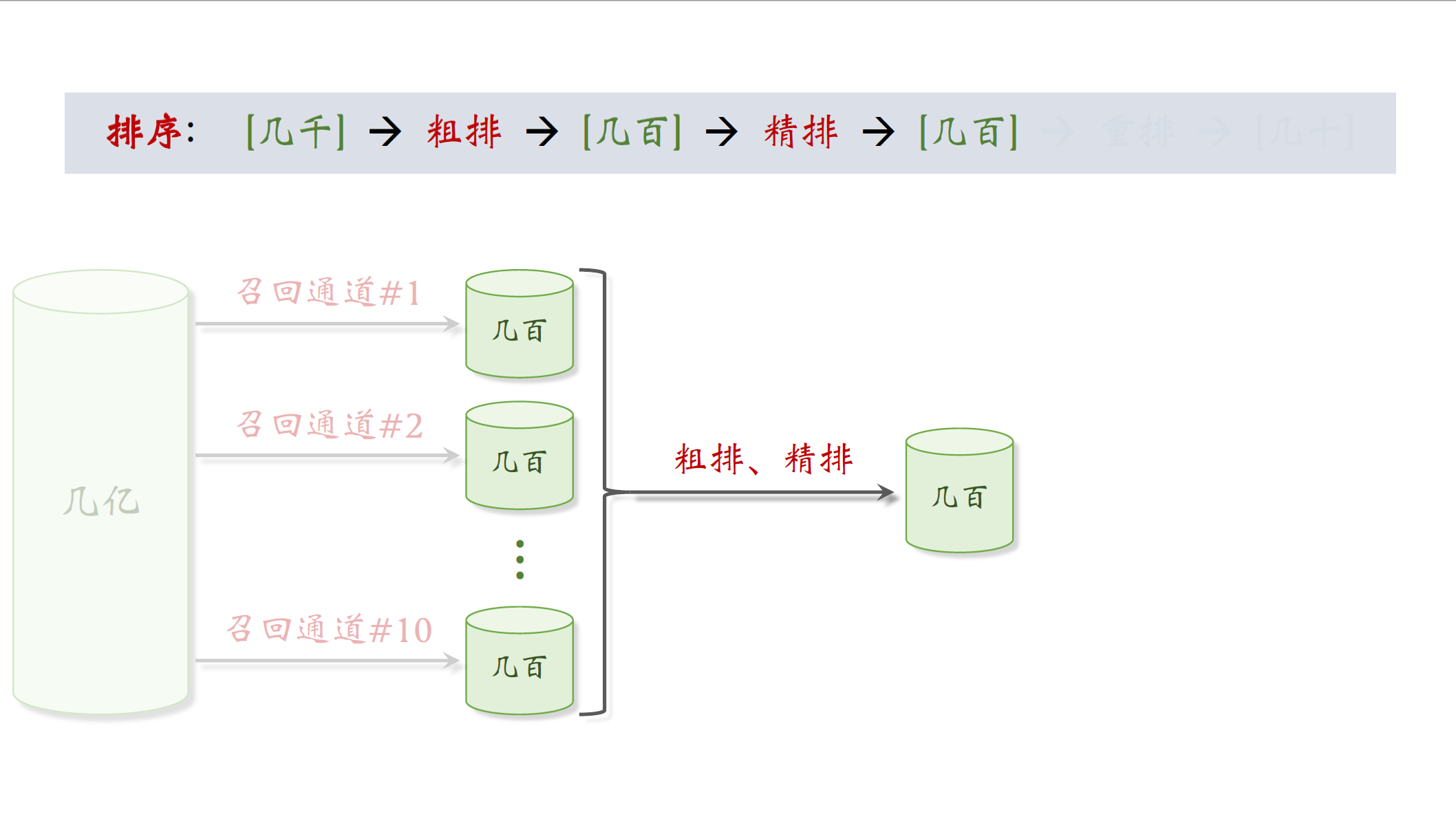
召回几千篇笔记后是做排序,排序要用机器学习模型预估用户对笔记的兴趣,保留最高的笔记。如果使用大规模的神经网络对几千篇笔记逐一打分,会耗费很多计算资源。为了解决计算量的问题,通常把排序分为粗排和精排,粗排用比较简单的模型,快速给几千篇笔记打分,保留分数最高的几百篇笔记。精排用一个较大的神经网络给几百篇笔记打分,不用做截断。精排模型比粗排模型大很多,用的特征也更多,所以精排模型大的分数更可靠,但是精排的计算量很大。所以我们要先做粗排做筛选,然后再做精排,这样可以很好平衡计算量和准确性。
粗排和精排
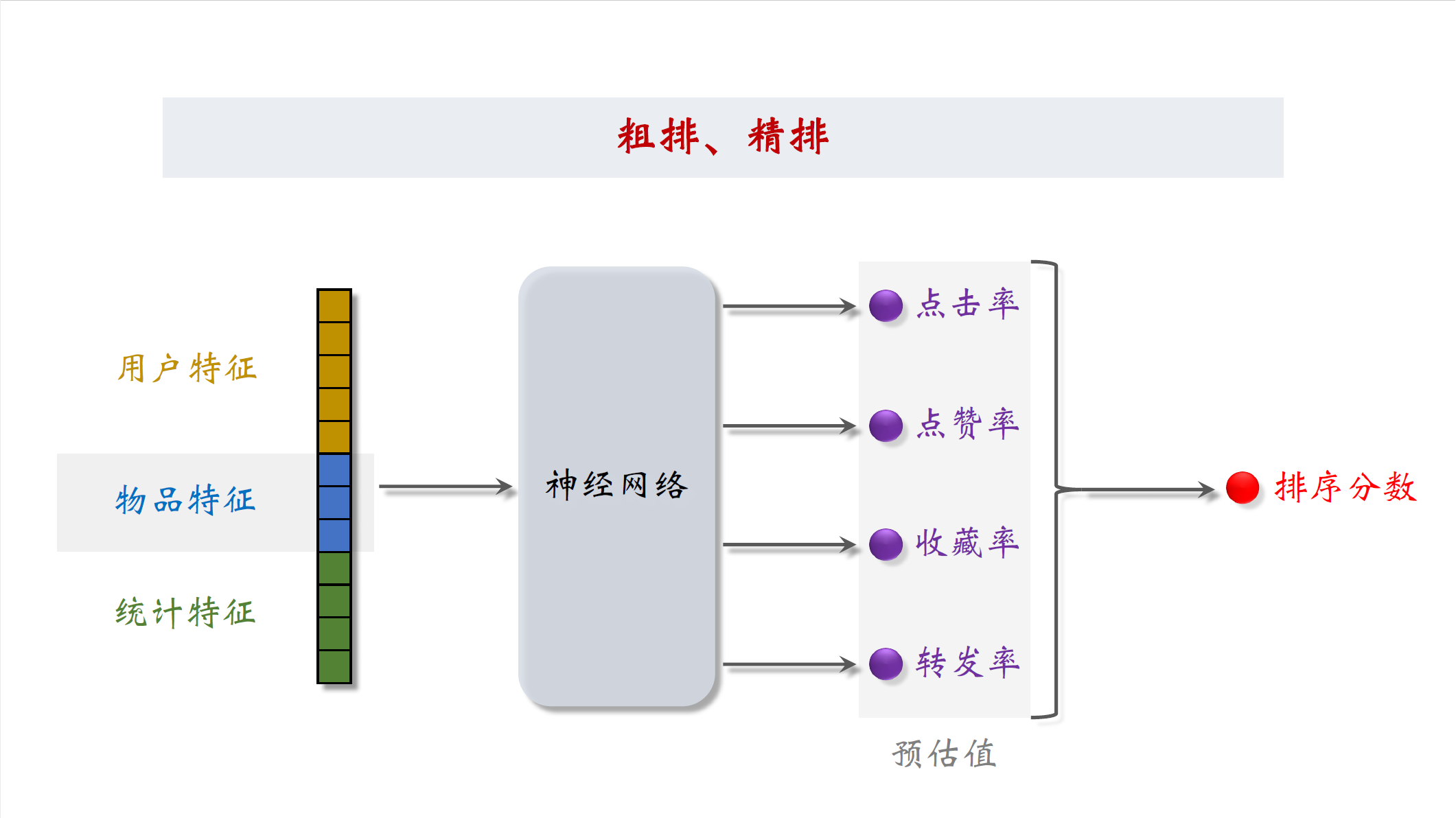
粗排和精排非常相似,唯一的区别就是精排的模型更大,使用的特征更多。模型的输入包括用户特征,物品特征和统计特征。假如我们要判断小王同学是否对笔记感兴趣,我们就要把笔记的特征,小王的特征和一些统计特征输入神经网络。神经网络会输出很多数值,比如:点击率,点赞率,收藏率和转发率。这些数值都是神经网络对用户行为的预估。这些数值越大说明用户对笔记越感兴趣,最后把多个预估值做融合,得到最终的分数,比如求加权和,这个分数决定了笔记会不会被展示给用户,以及笔记展示的位置靠前还是靠后。请注意这只是对一篇笔记的打分,粗排要对几千篇笔记打分,精排要对几百篇笔记打分。每篇笔记都有多个预估分数,融合为一个分数作为给这篇笔记排序的依据。
重排
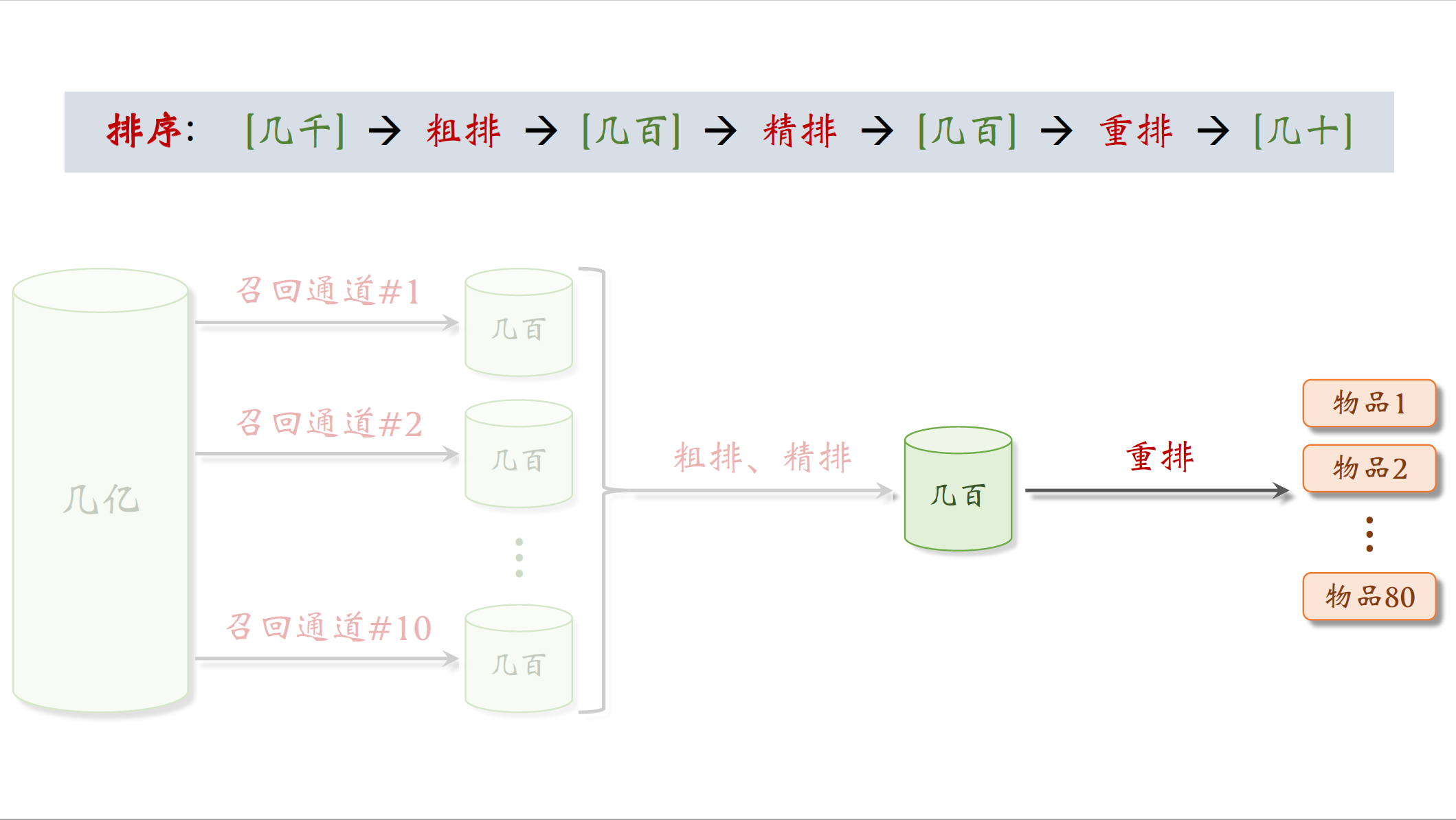
做完排序后的几百篇笔记会得到一个分数,代表用户对笔记的感兴趣程度,可以直接把笔记按照模型打的分数排序,然后展示给用户,但此时的结果还存在一些不足需要做一些调整,这一步叫做重排。重排主要是考虑多样性,要根据多样性做随机抽样。从几百篇笔记中选出几十篇,然后还要用规则把内容相似的笔记打散。重排的结果就是最终展示给用户的物品,比如把前八十的物品展示给用户,包括笔记和广告。
重排是做多样性抽样(比如MMR,DPP),从几百篇笔记中选出几十篇。抽样有两个依据,一个是精排分数的大小,另一个是多样性。做完抽样后会用规则打散相似内容,不能把内容过于相似的笔记排在相邻的位置上。举个例子:根据精排之后的分数,排在前五的笔记都是NBA的内容,这样就不太合适,即使用户是篮球球迷他也不希望看到同质化的内容,如果第一个是NBA的笔记,接下来几个位置就不能放NBA的内容,相似的笔记会往后挪。重排的另一个目的是插入广告和运营推广的内容,还要根据生态要求调整排序,比如不能连着出很多美女图片。
总结
