
Basic-推荐系统的AB测试
本博文引自王树森老师推荐系统。
视频地址:概要03:推荐系统的AB测试_哔哩哔哩_bilibili
课件地址: https://github.com/wangshusen/RecommenderSystem
推荐系统算法工程师的日常工作就是改进模型和策略目标是提升推荐系统的业务指标,所有对模型和策略的改进,都需要经过线上的A/B测试,用实验数据验证模型和策略是否有效。
召回团队实现了一种GNN召回通道,离线实验结果正向。但离线实验的结果有提升未必意味着线上实验也会有收益。做完离线实验,下一步是做线上的小流量A/B测试,也就是说,要把新的召回通道上线给用户使用观测用户的真实行为数据,比如日活留存点击交互。小流量:意思是把GNN召回通道只给一小部分用户使用,而不是全部的用户。
这是因为新的召回通道到效果怎么样还不清楚,有可能会严重损害用户体验,所以先给随机选的10%用户使用,而不是一上来就给所有用户使用。除了判断GNN召回通道能带来多大的业务指标收益,A/B测试还可以帮助我们选择最优的参数。比如,GNN神经网络的深度可以是一层两层三层,不同的参数会有不同的效果,我们可以同时开三组A/B测试,哪组实验效果好就用那组参数。
随机分桶

做A/B测试需要对用户做随机分桶,比方说把用户分成十个桶,那么每个桶中有10%的用户。如果用户的数量足够大,那么每个桶的的DAU,留存,点击率,这些指标都是相等的。具体怎么做分桶呢,首先用哈希函数,把用户id映射成某个区间内的整数,然后把这些整数均匀随机分成b个桶。
我们把用户随机分成十个桶,每个桶中有10%的用户,我们用这样的分桶做A/B测试,比方说我们想要考察GNN召回通道对业务指标的影响,我们用123号桶作为三个实验组, 但是GNN的参数不一样,三个桶的神经网络深度分别是一层,两层,三层,用4号桶作为对照组。这四个桶唯一的区别就是,前三个桶用了GNN召回通道,4号桶没有用GNN。如果一个用户落在了1号桶,那么给他做推荐的时候,会用1号桶的策略,使用一层的GNN神经网络做召回,如果另一个用户落在了4号桶,那么给他做推荐的时候,就不要用GNN做召回,分别计算每个桶的业务指标,比如DAU,人均使用推荐的时长,点击率等等。如果某个实验组的指标显著优于对照组,则说明策略有效,比方说第二桶的业务指标最好,而且跟对照组的diff(差异)具有显著性,这就说明两层的GNN召回通道是有效果的,值得推全。推全意思是把流量扩大到百分之百,给所有用户都使用两层GNN召回通道。
分层实验
刚才讲了AB测试的基本思想,接下来要讲分层实验,工业界实际上就是这么做的,分层实验的目标就是解决流量不够用的问题,我举个例子解释一下,比方说小红书有很多个部门,分别负责推荐系统,用户界面广告,每个部门有好几个团队,比如推荐系统有召回、粗排、精排、重排的团队,所有部门和团队都需要不断做实验,这样同时会做几十个上百个A/B测试。假如我们把用户随机分成十个桶,每个桶有10%的流量,取一个桶做对照组,剩下九个桶做实验组,那么线上最多只能同时开九个AB测试,根本无法满足产品迭代的需求,解决方案就是分层实验。
- 把实验分成很多层,比如分成召回、粗排、精排、重排、用户界面、广告这些层,例如之前召回通道就属于召回层。
- 同层的实验之间需要互斥。举个例子,GNN实验占用召回层的四个桶,那么其他实验只能用剩余的六个桶。同层互斥的目的是,避免一个用户同时被两个召回实验影响,假如两个实验相互干扰,实验结果会变得不可控。
- 不同层之间流量正交,每一层都独立随机对用户做分桶,每一层都可以独立用100%的用户做实验。召回和粗排的用户是独立随机划分的,召回的2号桶跟粗排的2号桶交集很小.

举个例子,召回层和精排层各自独立把用户分为十个桶,把召回的十个桶制作集合$u_1$到$u_{10}$,他们都是用户的集合,把精排的十个桶叫做集合$v_1$到$v_{10}$。设系统一共有n个用户,那么召回和金牌每个桶都有十分之n个用户,也就是说集合$u_i$和$v_j$的大小都是十分之n,把第$i$和$j$号召回桶记作$u_i$和$u_j$,他们的交集是空集,所以同一层实验之间是互斥的,两个召回实验不会同时作用到一个用户上。召回桶$u_i$和精排桶$v_g$各自大小都是十分之n,他们交集的大小是n%。一个用户不能同时受两个召回实验的影响,但可以同时受一个召回实验和一个精排实验的影响。一个召回实验和一个精排实验,各自作用在十分之n个用户上,那么有n%的用户同时受两个实验的影响,也就是说不同层正交。
我画个图再解释一遍,同层互斥和不同层正交,对于召回层,把用户随机分成十个桶,每个桶有10%的用户,如果GNN的实验占了四个桶,那么其他实验只能用剩余的六个桶,两组召回实验的用户是隔离开的,两组召回实验不能同时做到一个用户上。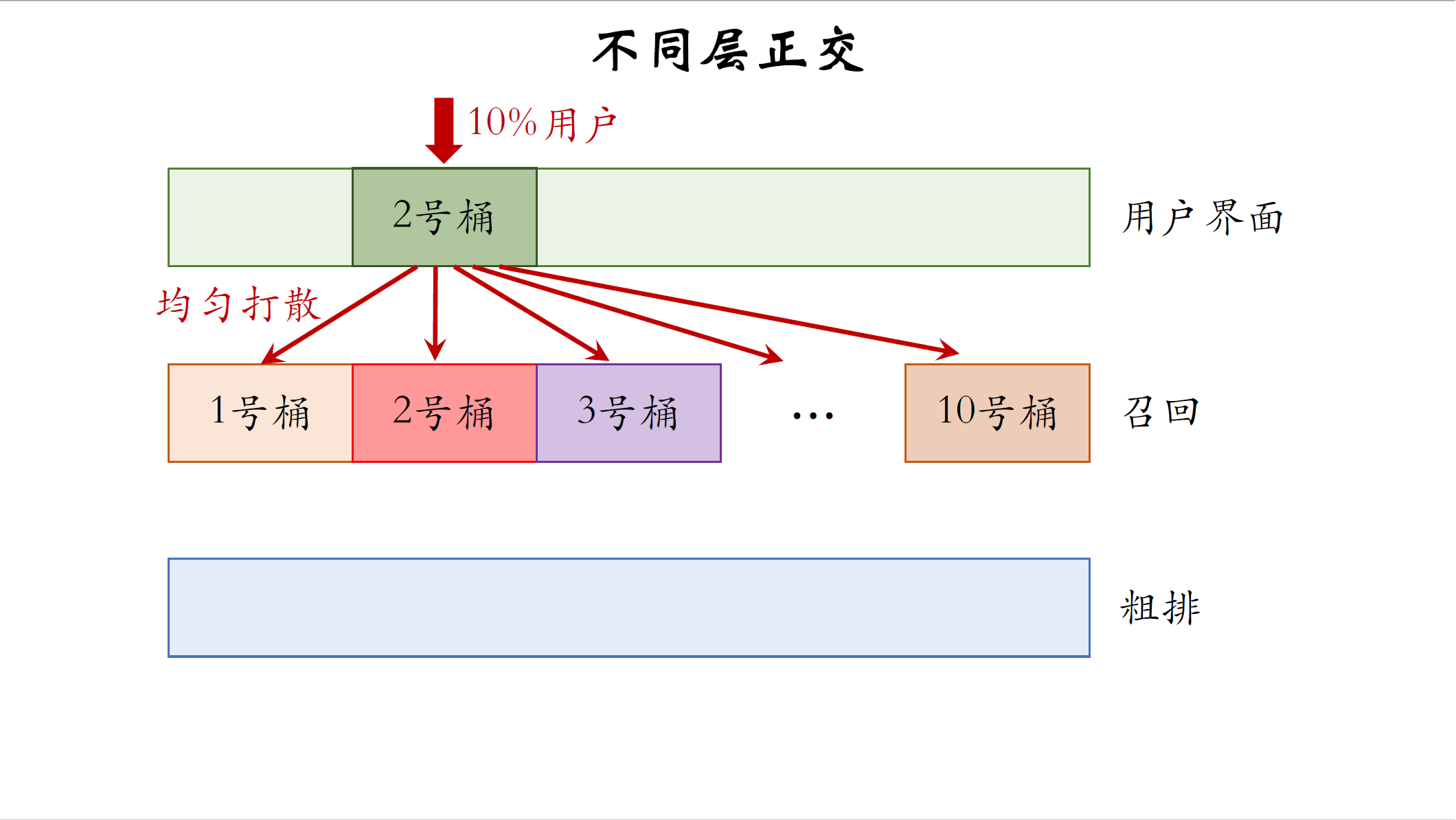
不同层之间正交,比方说用户界面层2号桶,有10%的用户。层之间的分桶是随机独立的,所以用户界面层2号桶的用户被均匀打散到了召回层的十个桶。也就是说,用户界面的一个实验和召回的一个实验,可能会同时作用到一个用户身上。通常来说,用户界面实验和召回实验的效果,不容易相互增强或者相互抵消,所以我们允许一个用户同时受两层实验的影响。
如果所有实验全都用正交,不用互斥,那么就可以同时做无数组实验,既然正交有好处,为什么不能全都用正交呢。我再解释一下, 为什么要有互斥和正交这两种设定,而不能全都用正交。
用互斥的一个原因是,有的同类策略天然就互斥,不可能做到正交,比如对精排模型两种结构优化策略,天然就是互斥的。对同一个用户,不可能同时把两种精排模型结构都用上,只能给一组用户用第一种结构,给另一组用户用第二种结构,也就是做互斥的实验。
用互斥的另一个原因是,同类的策略之间相互会有影响。举个例子,可以推荐系统添加两条召回通道,两条召回通道并不排他,两条召回通道可以同时作用到一个用户上。比如这个用户的召回通道数量,从50增加到52,但是这样同类型的策略最好还是做互斥实验,避免相互的干扰,两组召回实验可能会同时发生作用,相互加强或者相互抵消,如果两条召回通道是互补的,那么1+1可能会大于二,效果相互增强;如果两条召回通道相似,那么添加两条召回通道,跟添加一条效果基本一样,两者会抵消1+1可能只等于一。如果不把两组实验用户做隔离,那么两组实验会同时作用到一部分用户上,测出的实验组和对照组的地方会不准。详细原因我不解释了,感兴趣的话可以看我放在github上的讲义。
不同类型的策略通常不会相互干扰,可以把它们作为正交的两层,同时作用到某些用户上。比如有两种策略,一种是添加召回通道,另一种是优化粗排模型结构,两个策略效果通常是1+1=2,于是可以把召回作为一层,把粗排作为一层,两层正交,各自都可以用百分之百的用户做实验。
Holdout机制

前面讲了A/B测试的基本原理和分层实验,接下来介绍Holdout机制。推荐系统有很多环节,比如召回、粗排、精排、重排,其实还有很多业务场景,每个业务场景都有自己一条链路,现场同一时间至少有几十个推进系统的实验,一个实验通常有一两个算法工程师负责,如果有效,那么就是算法工程师自己的业绩,公司需要考察一个部门,在一段时间内对业务指标总体的提升。比如推荐部门在两个月的成果,不能简单的把所有推荐实验的指标,收益都加起来作为部门整体业绩,这样相加是不可信的。实验叠加到一起通常会有折损,所以需要Holdout机制,取10%的用户作为holdout桶,相当于对照组。整个推荐系统使用剩余的90%用户做实验,跟holdout桶互斥,只要算一下两者的diff,就知道整个推荐部门的业务指标收益了,当然想用10%跟90%做对比,需要对指标做个归一化。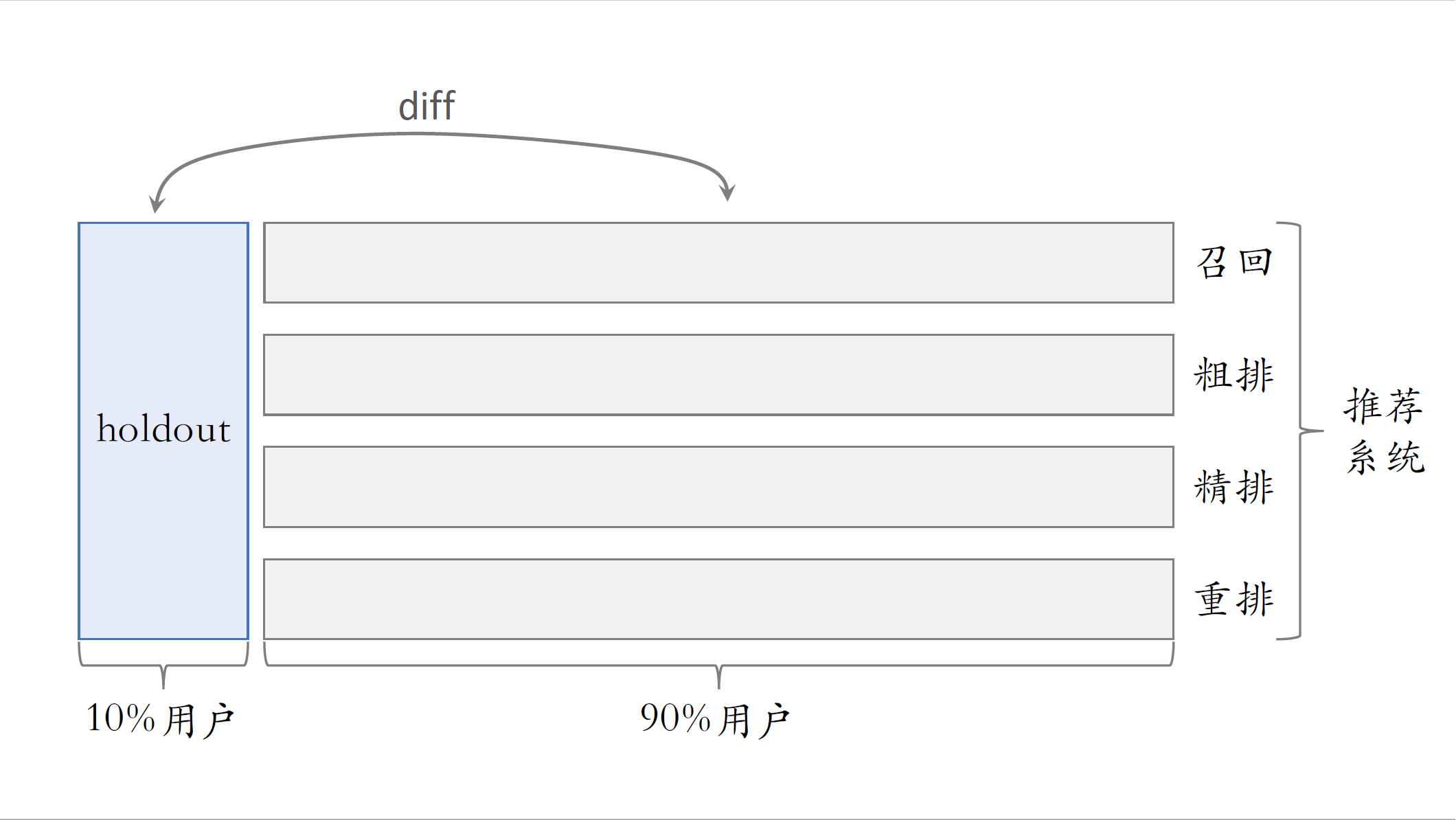
具体是这样做分层整个大的系统分成推荐系统,用户界面,广告等很多大层,这些层之间正交。在推荐系统层,把用户随机分成两个桶,把10%的用户作为holdout,这个桶是干净的,任何新的实验都不能作用到holdout用户。用剩余90%用户做实验,把这些用户细分成四层,有召回、粗排、精排、重排,这些层之间正交,也就是说,召回可以用全部90%的用户做实验,粗排也可以用全部90%的用户做实验。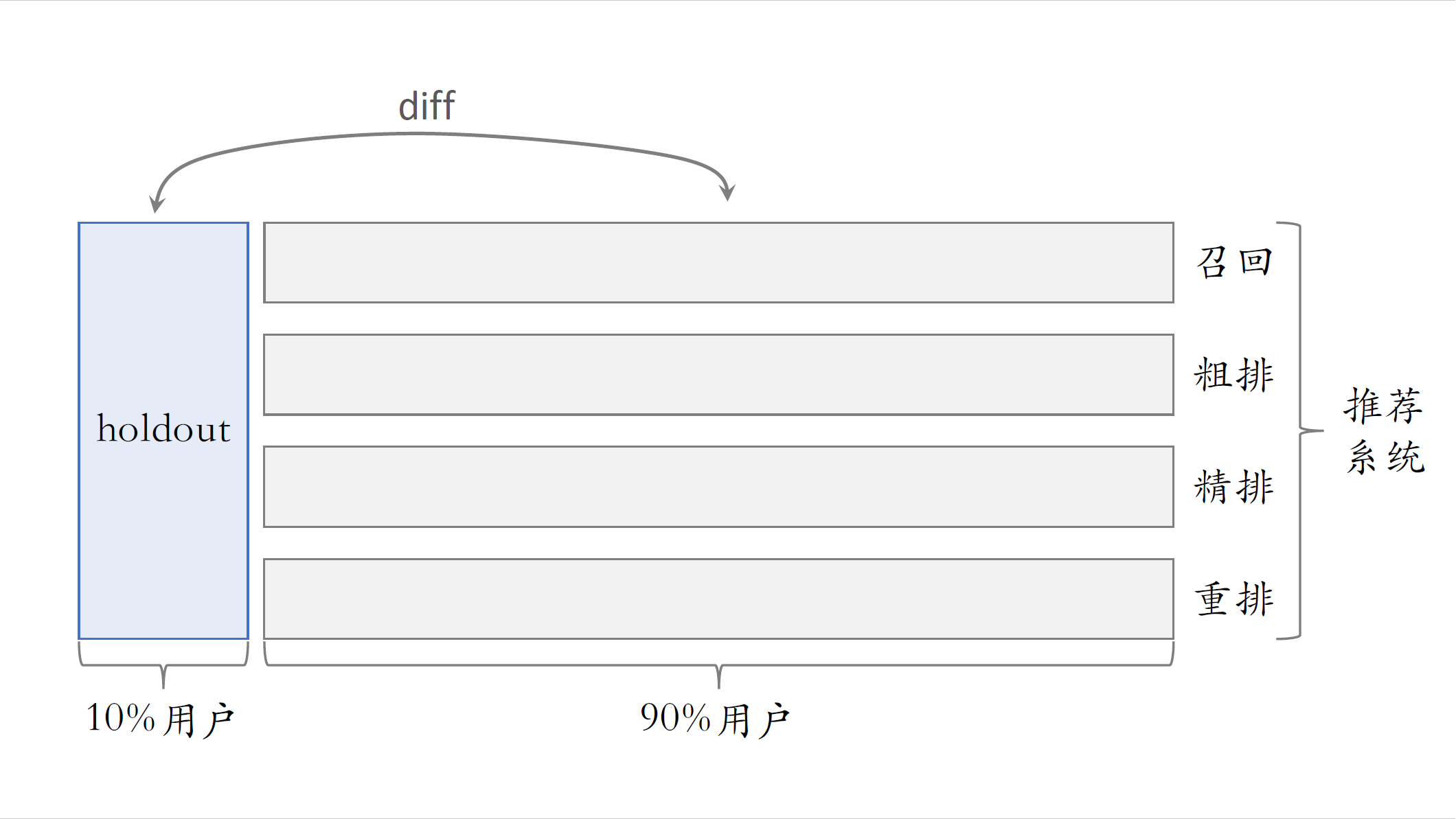
召回、粗排、精排、重排的有效实验,均会带来两边指标的diff,而且多个实验贡献的diff会叠加,如果公司以双月作为考核周期,那么每两个月结束的时候计算90%实验桶和10%holdout桶各种指标的diff,作为整个推荐部门对业务指标的贡献。
在每个考核周期结束之后会清除houldout桶,也就是上推全的实验,从90%用户扩大到100%的用户。然后随机重新划分用户,得到新的holdout桶和实验桶开始下一轮考核周期。由于划分是随机均匀的,新的holdout桶和实验桶的各种指标的diff几乎为零,可以开始公平的实验对比。在新的考核周期开始之后,会有召回、粗排、精排、重排的实验上线,有的实验会取得收益,并且推全。所有实验的收益都会叠加,让实验桶与holdout桶的diff逐渐扩大。
实验推全
这节课最后一部分内容是实验推全和反转实验。推荐系统中所有实验都是从小流量开始的,如果业务指标的diff显著正向,则可以推全实验。
这里举个例子,我们做一个重排策略的实验。取一个桶作为实验组,一个桶作为对照组,实验一共影响了20%的用户,如果观测到显著正向的业务指标收益,则可以推全这个策略。把重排层的实验给关掉,这样就能把两个桶空出来,给其他实验用。
推全的时候新开一层。新策略会影响全部90%的用户,在小流量阶段,新策略作用到10%的用户上,会微弱的提升实验桶与houldout桶的diff。推全之后,新策略作用到90%的用户上,那么diff会扩大九倍。比方说AB测试发现,新策略会提升点击率九个万分点,小流量实验只作用到10%的用户上,所以只能把跟holdout桶的diff提升一个万分点。推全之后,理论上可以把def提升到九个万分点,跟AB测试得到的数据一致。
反转实验

接下来我要讲反转实验,上线一个有效的策略之后, 需要观测很多业务指标。有的指标立刻会被新策略影响,而有的指标会有滞后性。比如点击率,点赞率,完播率等指标会立刻被新策略影响,实验上限一天或者实验上限十天,观测到指标差距不会太大。用户使用推荐的时长,人均阅读量,这些指标有点滞后,需要多观察几天指标才能稳定,用户留存指标滞后非常严重,有可能短期内观测不到显著变化,但在之后几个月会持续改善。指标滞后的原因不难理解,新策略改善用户体验需要过一段时间才能被用户感受到,感受到之后,用户对产品的粘性才会越来越高。也就是说实验观测的越久越好,可以让观测到的指标更准确。但算法工程师希望在关系到显著收益之后,一两周就推全实验,这样有很多好处。可以腾出桶来供其他实验使用,还可以基于新策略做后续实验。也就是说尽快推全有好处, 把实验保留很久也有好处, 这就是一对矛盾。实践中常用反转实验解决这对矛盾,用反转实验的话,既可以尽快推全,也可以长期观测实验指标。具体做法是在推全的新层中开一个旧策略的桶,这样就可以长期观测实验指标。
我画一下反转实验的示意图,这是为推全新策略开的新层。新层与召回、粗排、精排、重排,这些层都正交,可以在这个新层里开一个很小的反转桶,桶里的用户都用旧策略,可以把反转桶保留很久,长期观察新策略与旧策略的diff。一个考核周期结束之后会清除掉holdout桶,但这不会影响反转桶。清除holdout,会把推全的新策略应用到holdout的用户上,不会影响反转桶。当反转实验完成时,关闭反转实验,新策略会应用到反转桶的用户上,也就是实现真正推全,对所有用户都生效。
总结

最后总结一下这节课的内容,分层实验是工业界通用的做法,把容易相互增强或者相互抵消的实验放在同一层,比如把召回放在一层,把精排模型放在一层。同层互斥,意思是不允许同层的两个实验,同时影响同一位用户。不同层正交,意思是不同层的实验可以有重叠的用户。holdout也是工业界通用的机制,比如用来考察整个推荐部门,在两个月内对业务指标总的贡献。单独留出一个holdout桶,保留10%的用户,他们完全不受实验的影响,实验都在其他90%用户上做。所有的实验都是从小流量开始,如果策略有效,最终会被推全。推全,意思是扩大到90%的流量上,每推全一个策略都会新建一个推全层,覆盖90%用户,它跟其他层正交。反转实验是为了在尽早推全新策略的同时,还能长期观察各种指标。具体做法是,在新的推全层上保留一个小的反转桶,反转桶里的用户使用旧策略。可以把反转桶保留很久, 长期观察新旧策略的diff。
这节课介绍了AB测试的基础知识,以及工业界实际的做法,这节课就讲到这里,感谢大家观看。