
召回02:Swing模型
本博文引自王树森老师推荐系统。
视频地址:召回02:Swing 模型_哔哩哔哩_bilibili
课件地址: https://github.com/wangshusen/RecommenderSystem
回顾ItemCF
上节课的内容是基于物品的协同过滤,缩写是ItemCF。这节课介绍ItemCF的一个变体叫做Swing,在工业界很常用,Swing跟ItemCF非常像,唯一的区别就是怎么样定义物品的相似度,回顾一下上节课介绍的ItemCF。
ItemCF,这样定义两个物品之间的相似度,如果喜欢物品$i_1$和$i_2$的用户有很大的重叠,那么判定物品$i_1$与$i_2$ 相似,ItemCF基于这样的假设,如果用户喜欢物品$i_1$,而且物品$i_1$与$i_2$相似,那么用户很可能也喜欢物品$i_2$。ItemCF就是基于这样的假设做推荐。
再复习一下ItemCF计算两个物品相似度的公式,把喜欢物品$i_1$的用户记作集合$w_1$,$w_1$是用户的集合,把喜欢物品$i_2$的用户记作集合$w_2$,把集合$w_1$ $w_2$ 的交集记作$V$。集合$V$中的用户,同时喜欢物品$i_1$和$i_2$,用这个公式计算物品$i_1$,$i_2$的相似度,公式中的分子是集合$V$的大小,即对两个物品都感兴趣的用户人数。分母是集合$w_1$ $w_2$ 的大小的乘积,再取根号,这样计算出的相似度一定是一个介于0~1之间的数,数值越大,表示两个物品越相似。
我画个图来解释ItemCF的物品相似度,左右两边各是一个物品,这六个人是用户。推荐系统记录了用户对哪些物品感兴趣,比方说用户给一个物品点赞,就说明用户对物品感兴趣,这五个箭头表示有五个用户对左边红色物品感兴趣,这五个箭头表示用户对右边的绿色物品感兴趣,这四个用户就是前面定义的交集$V$,它是两组用户重合的部分,集合$V$中的用户同时对两个物品都感兴趣,集合$V$中这部分的用户占比越大,ItemCF就认为两个物品的相似度越高。通常来说这是有道理的,如果大量的用户同时喜欢两个物品,那么这两个物品应该有某种共性,比方说左边的物品是骂川普的文章,右边的物品是支持绿色能源的文章,两篇文章字面上没啥相似性,但使用ItemCF会发现两者之间的相似度非常高。这是有道理的,如果一个用户喜欢看支持绿色能源的文章,那么给他推骂川普的文章,他也很有可能会点击和点赞。举个反例,一篇文章骂川普,一篇文章支持川普,两篇文章字面上特别像,但是ItemCF会发现两篇文章的相似度非常低,给支持川普文章点赞的,绝对不可能给骂川普的文章点赞。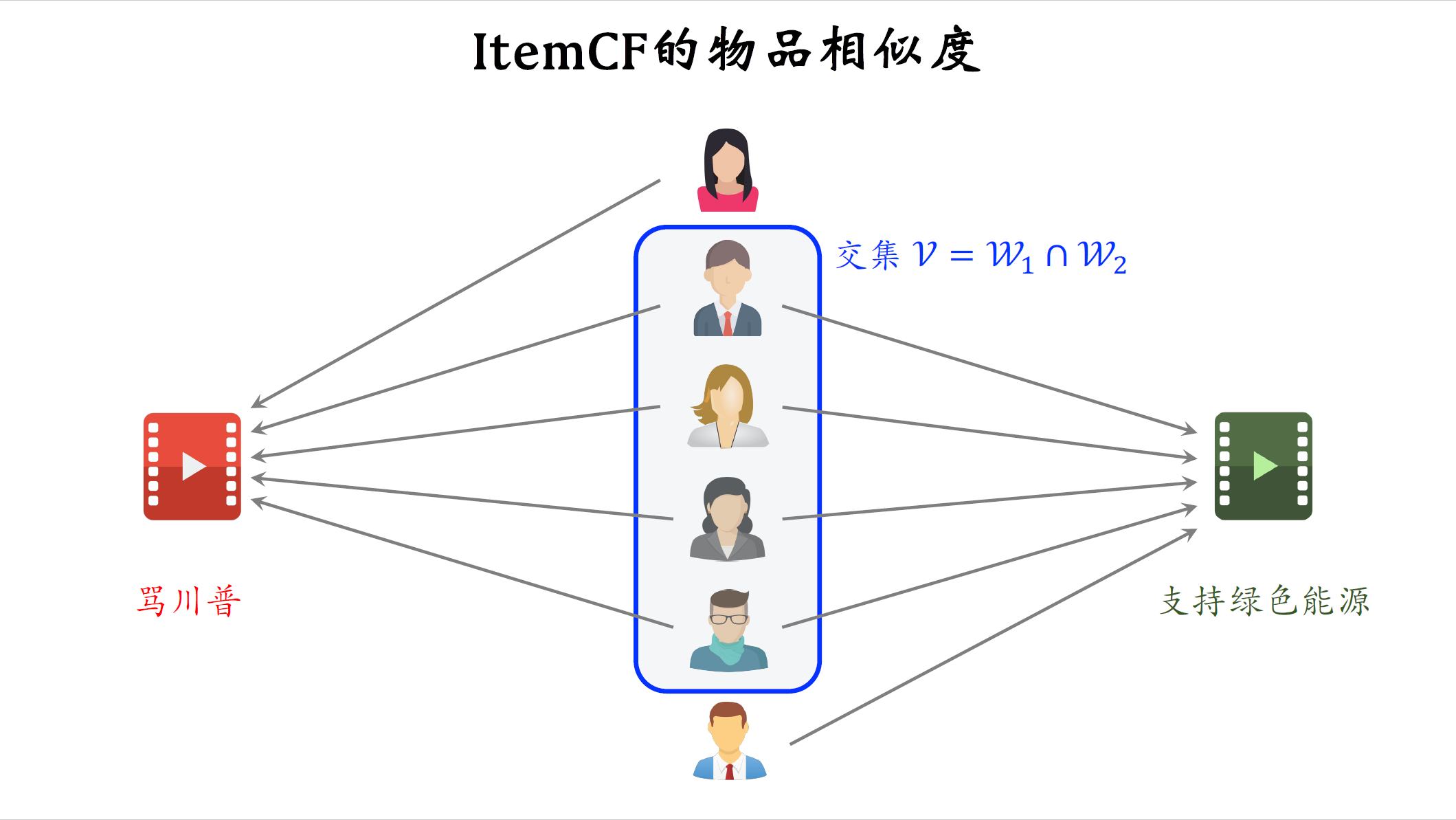
刚才回顾了ItemCF的原理,下面讨论ItemCF的不足之处,问题在于,假如重合的用户是一个小圈子该怎么办,比方说这四个用户都在同一个微信群里面,左边的物品是这样一篇笔记,某网站护肤品打折,右边的物品是笔记,字节裁员了,这两篇笔记没有什么相似之处,他们的受众差别很大,但是两篇笔记碰巧被分享到同一个微信群里面,微信群里有很多人同时点开这两篇笔记,这样就造成一个问题,两篇笔记的受众完全不同,但是很多用户同时交互过两篇笔记,导致系统错误的判断,两篇笔记的相似度很高,想要解决这个问题,就要降低小圈子用户的权重,我们希望两个物品重合的用户广泛而且多样,而不是集中在一个小圈子里,一个小圈子的用户同时交互两个物品,不能说明两个物品相似,反过来,如果大量不相关的用户同时交互两个物品,则说明两个物品有相同的受众。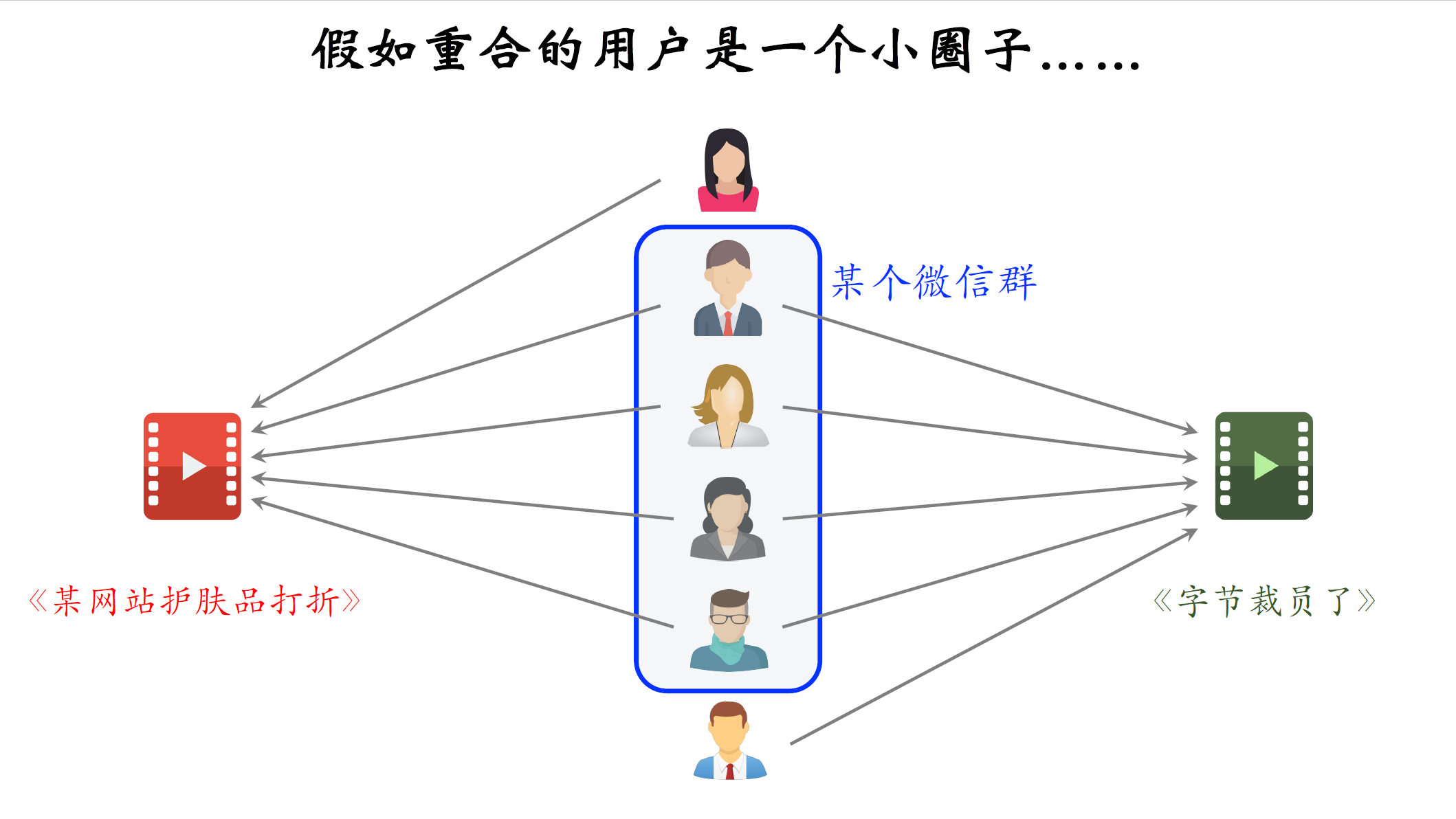
Swing模型
Swing模型的原理就是给用户设置权重,解决小圈子问题。接下来我具体讲Swing模型是怎么样计算两个物品的相似度,把用户$u_1$ 喜欢的物品记作集合$J_1$,把用户$u_2$ 喜欢的物品记作集合$J_2$,定义两个用户重合度为$J_1$与$J_2$的交集的大小,记住overlap ($u_1$ , $u_2$ ) 。这个值越大,说明两个用户的重合度越高,越有可能是一个小圈子的人,要降低他们的权重,在计算物品相似度的时候,会把overlap ($u_1$ , $u_2$ ) 放到分母上。
把喜欢物品$i_1$的用户记作集合$w_1$ ,把喜欢物品$i_2$的用户记作集合$w_2$ ,集合$V$是$w_1$和$w_2$ 的交集,如果一个用户既喜欢物品$i_1$也喜欢物品$i_2$,那么这个用户就在集合$V$中.下面是计算两个物品相似度的公式,sim($i_1,$$i_2$)意思是物品$i_1$和$i_2$两者的相似度,计算相似度的时候,要关于集合大$V$中的用户求连加,把用户记作$u_1$ 和$u_2$ ,它们都属于集合大$V$,也就是说用户$u_1$ $u_2$ 都对物品$i_1$ $i_2$感兴趣,这种用户越多,就说明物品$i_1$ $和$ $i_2$越相似,连加里面是$\frac1{\alpha + overlap(u_1 +u_2)}$。$\alpha$是个人工设置的参数,需要调,overlap的意思是用户$u_1$ 和$u_2$ 的重叠有多大,重叠大说明两个人是一个小圈子的,那么他们两个人对相似度的贡献会比较小,反过来如果overlap小,那他们对相似度的贡献比较大,用overlap可以降低小圈子对相似度的影响。
总结
最后总结一下这节课的内容,Swing和ItemCF是非常相似的两种方法,它们唯一的区别就是在于如何计算物品的相似度,ItemCF考察两个物品重合的受众比例有多高,如果很多用户同时喜欢两个物品,则判定两个物品相似;Swing跟ItemCF差不多,但是会额外考虑重合的用户是否来自同一个小圈子,把同时喜欢两个物品的用户制作集合$V$,对于集合$V$中的用户$u_1$ 和$u_2$ ,把两个用户的重合度记作overlap($u_1$ ,$u_2$ ) ,overlap越大,说明两个用户越有可能来自同一个小圈子,那么就要降低他们的权重,他们对物品相似度的分数的贡献就会比较小。总而言之,Swing跟ItemCF的区别就是在计算物品相似度的时候,要降低小圈子用户的影响,这节课就讲到这里,下节课介绍基于用户的协同过滤。