
召回04:离散特征处理
本博文引自王树森老师推荐系统。
视频地址:召回04:离散特征处理_哔哩哔哩_bilibili
课件地址: https://github.com/wangshusen/RecommenderSystem
前面几节课介绍几种协同过滤的召回方法,后面几节课要介绍向量召回,在讲向量召回之前,大家先熟悉一下离散特征的处理,这节课的重点是one-hot的编码和embedding,有机器学习基础的同学可以跳过这节课。
离散特征处理
离散特征在推荐系统中非常常见,性别是离散特征,分为男女两种类别,国籍是离散特征,比如中国、美国、印度,一共有200个左右的国家,英文单词是离散特征,常见的英文单词有几万个,物品ID是离散特征,比如小红书有几亿篇笔记,每篇笔记有一个ID这样的离散特征处理比较困难,因为类别数量实在太大了,用户ID也一样,小红书有几亿个用户,每个用户有一个ID,推荐系统会把一个ID映射成一个向量。
离散特征的处理分两步,第一步是建立字典,把类别映射成序号。以国籍特征为例,建立一个国家的字典,比如中国序号是1,美国序号是2,印度序号是3.第二步是做向量化,把序号映射成向量。one-hot编码是一种常见的方法,把序号映射成高维的稀疏向量,比如有200个国家,每个国家被映射成一个200维的向量,序号对应的位置的元素是1,其他位置的元素都是0,更高级的方法是embedding,把序号映射成低为稠密向量,比如处理国籍特征,每个国家被映射成一个八维的稠密向量。
One-Hot编码
后面的内容分两部分,先是one-hot的编码,然后是embedding。第一个例子是性别特征,性别分为男女两种,那么字典里只有两个元素,男性的序号是1,女性的序号是2。one-hot编码用二维向量表示性别,如果用户不填性别,那么序号就是零,然后用全零向量表示,如果用户性别是男,那么序号就是1,用向量10表示,如果性别是女,序号就是2,用向量01表示.第二个例子是国籍特征,假设有200个国籍,比如中国、美国,印度等等,字典里有200个国家,每个国家有一个序号,比如中国是1,美国是2,印度是3。one-hot编码,用200维的稀疏向量表示国籍未知的国际区号是0,用全零向量表示。中国的序号是1,one-hot向量只有第一个元素是1,其余元素全都是0。美国的序号是2,one-hot向量只有第二个元素是1,其余元素都是0。同理印度序号是3,one-hot向量只有第三个元素是1。
one-hot编码很常用,但是它有一定的局限性。比如在自然语言处理的应用中,需要对单词做编码,新闻至少有几万个常见的单词,那么one-hot向量的维度就是几万,这个维度是很大的,实践中通常不会用这么高维的向量。推荐系统中需要对物品的ID做编码,物品的数量很大,比如小红书有几亿篇笔记,那么one-hot向量的维度就是几亿,在实践中更难处理,在实践中类别数量太大的时候,通常不用one-hot编码。 对于性别这样的离散特征,类别数量很小,可以直接用one-hot向量,但是对于单词、物品ID这样的离散特征类别数量巨大,用one-hot向量并不合适,更常见的做法是embedding,即把每个类别映射成一个低维的稠密向量。
Embedding(嵌入)
下面我介绍embedding,它是另一种把序号映射成向量的方法,embedding翻译成嵌入。我用两个例子讲解embedding,第一个例子是国籍,字典里有中国,美国,印度,日本,德国等200个国家字典,把每个国家映射成一个序号,比如中国是1,美国是2,印度是3,一,共有200个序号,embedding把每个序号映射成一个向量,这些向量都是低维向量,比如向量大小都是4x1,一个向量就是对一个国家的表示,未知国籍就用全零向量表示。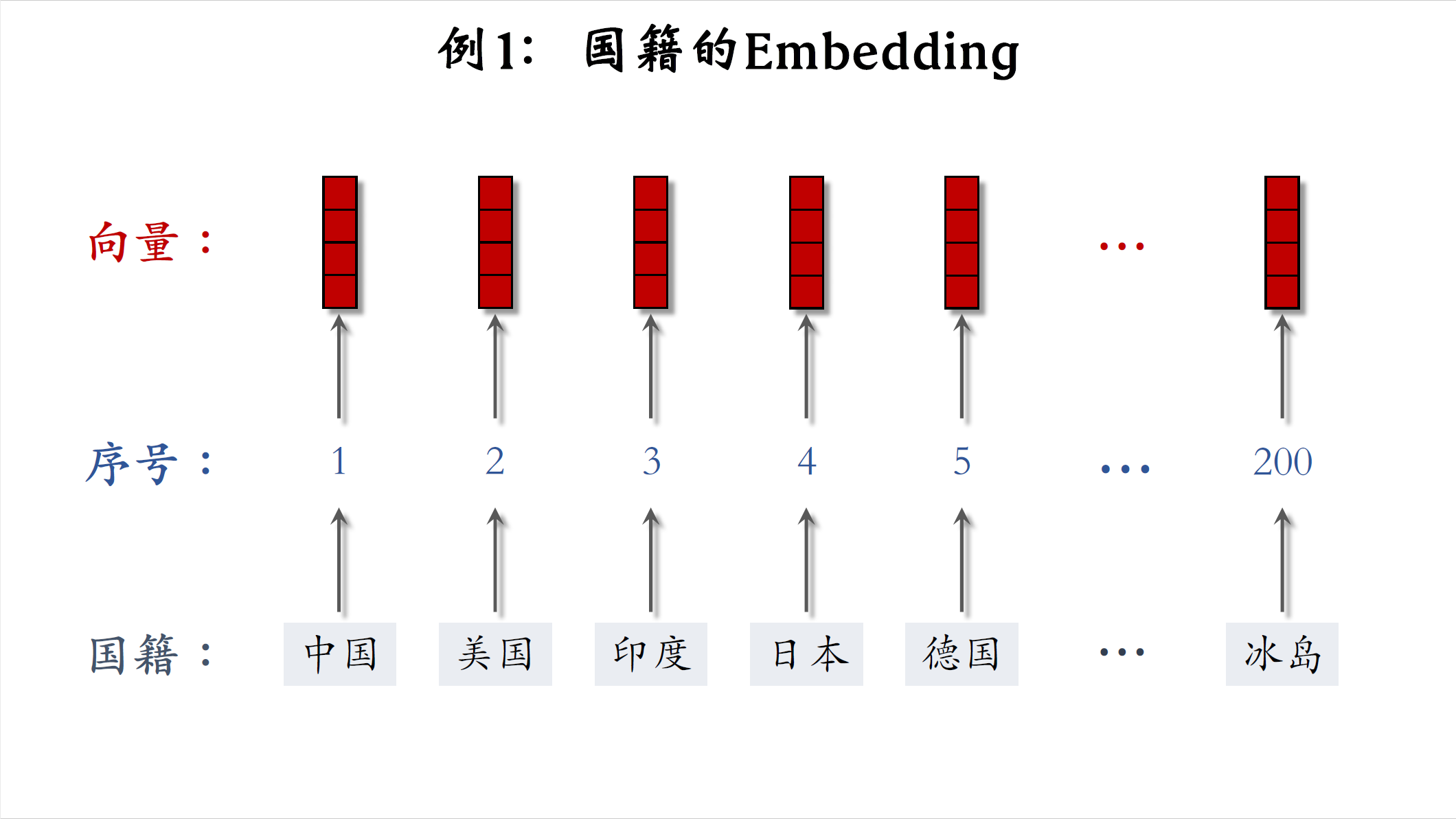
我们来分析一下参数的数量,结论是embedding的参数是一个矩阵,大小是向量维度乘以类别数量,假设embedding得到的向量都是四维的,一共有200个国籍,那么就有200个向量参数的数量是4x200=800,编程实现的话,可以用tensorflow pyt直接系统提供的embedding层,在训练神经网络的时候会自动做反向传播,embedding层的参数是一个矩阵,矩阵的大小是向量维度乘以类别数量,embedding层的输入是序号,比如美国的序号是2,embedding层的输出是个向量,即参数矩阵的一列,比如美国对应参数矩阵的第二列。
第二个例子是物品ID的embedding,假设物品的数据库里一共有1万部电影,推荐系统的任务是给用户推荐电影,设embedding向量的维度是16,也就是说用一个16位的向量表征一部电影。我们来思考一个问题,embedding层一共有多少参数,参数的数量等于向量维度乘以类别数量,16x10000=160000,这就是embedding层参数的数量,如果类别的数量不大,只有几百万,那么embedding的实现是比较容易的,tensorflow和pytorch都可以处理的很好,但如果类别数量特别大,比如推荐系统中的物品数量有几十亿,那么embedding层会特别大,一个神经网络绝大多数的参数都在embedding层,所以工业界深度学习系统都会对embedding层做很多优化,这是存储和计算效率的关键所在。
我画个示意图说明embedding得到的向量的物理意义,推荐系统具体怎么样训练embedding层,我下节课再讲.图中的每个点表示一部电影的embedding,如果训练的好,从物品的embedding可以看出物品的特点。比如这些点都是动画片,它们的距离比较近,这些点都是间谍片,他们离得比较近,但是间谍片和动画片之间的距离会比较远。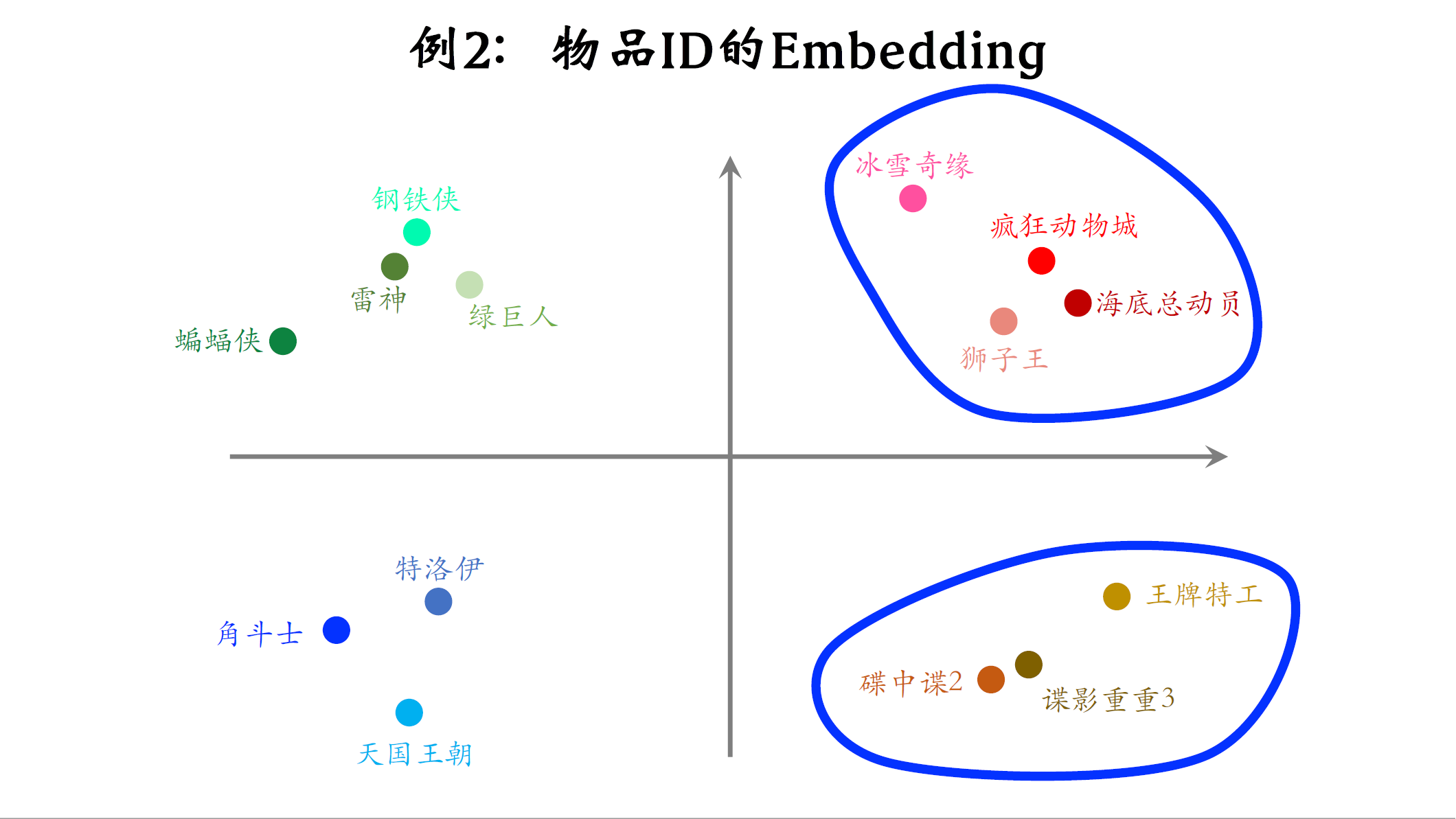
最后讲讲embedding和one-hot编码之间的关系,embedding其实就是把one-hot的向量乘到一个参数矩阵上,举个例子,这是个one-hot的向量,它的第三个元素是一,其余元素全都是零,这是embedding的参数矩阵,把矩阵和one-hot向量相乘,由于one-hot向量只有第三个元素非零,所以矩阵向量乘法其实就是取出矩阵的第三列,把第三列作为输出,输出的向量就是参数矩阵跟one-hot向量的乘积,从这个角度看,embedding其实就是矩阵向量乘法跟全连接层非常像。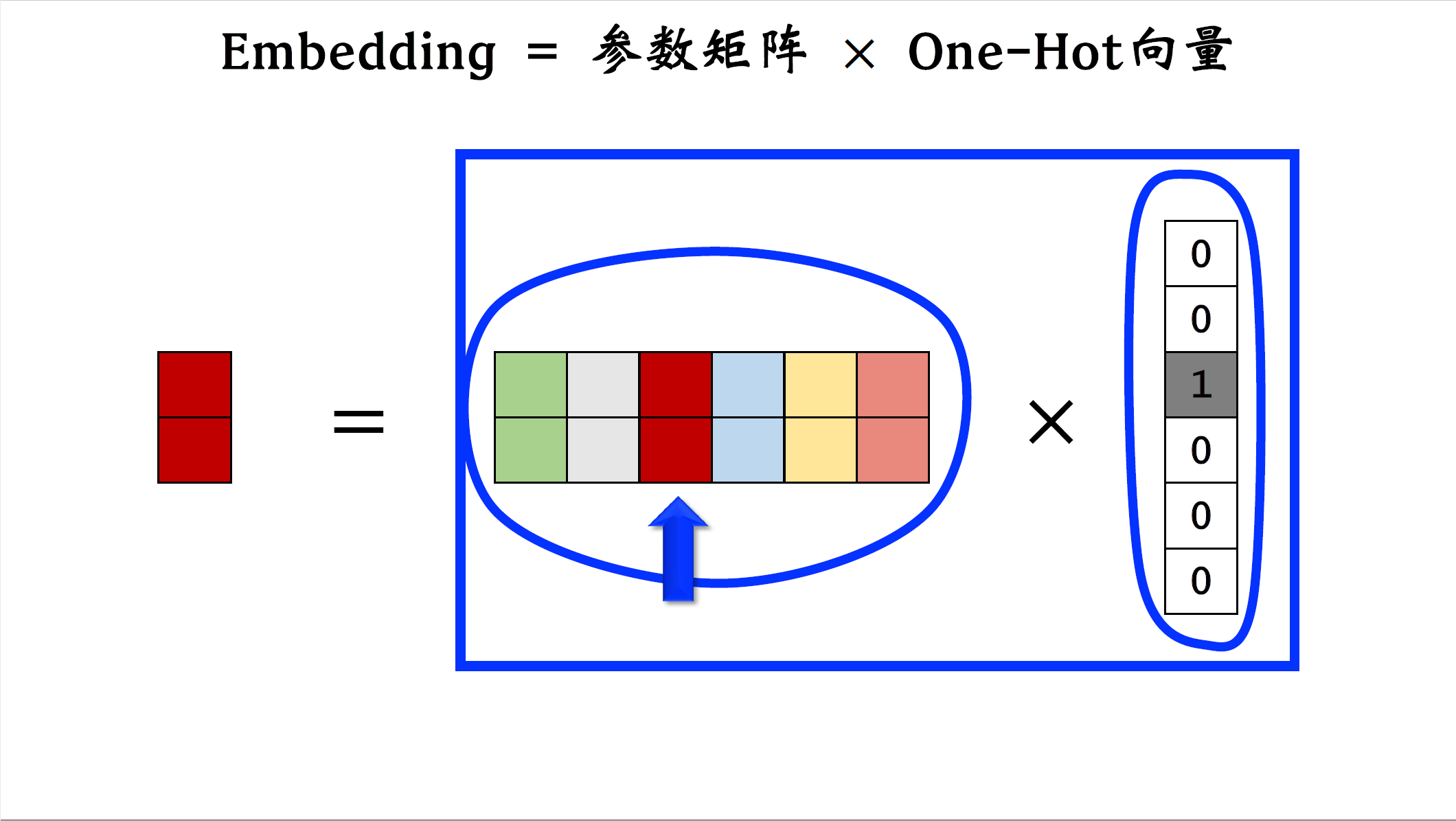
最后总结一下这节课的内容,这节课主要讨论了离散特征的处理,有两种常用的离散特征处理方法,一种是one-hot编码,一种是embedding。类别数量很大的情况下,一般都用embedding,比较常见的例子是word
embedding,用户ID embedding,物品ID embedding。这节课的内容就讲到这里,感谢大家观看,后面几节课介绍,向量召回要用到这节课的知识。