
召回05:矩阵补充、最近邻查找
本博文引自王树森老师推荐系统。
视频地址:召回05:矩阵补充、最近邻查找_哔哩哔哩_bilibili
课件地址: https://github.com/wangshusen/RecommenderSystem
这节课后面几节课详细讲解向量召回,矩阵补充是向量召回最简单的一种方法,不过现在已经不太常用这种方法了,我讲解矩阵补充是为了帮助大家理解下节课的双塔模型,大家可能早就熟悉矩阵补充,但我还是建议大家把这节课看完,我会讲很多教科书里没有写,但是在工业界非常有用的知识点。
复习
上节课介绍了$embedding$,他可以把用户ID或者物品ID映射成向量,我画的这个模型就是基于$embedding$做推荐,模型的输入是一个用户ID和一个物品ID,模型的输出是一个实数,是用户对物品兴趣的预估值,这个数越大,表示用户对物品越感兴趣。
下面我们看一下模型的结构,左边的结构只有一个$embedding$层,把一个用户ID映射到一个向量,记住向量a这个向量是对用户的表征,回忆一下上节课的内容,$embedding$层的参数是一个矩阵,矩阵中列的数量是用户数量,每一列都是图中a这么大的向量,$embedding$层的参数数量等于用户数量乘以向量a的大小。右边的结构是另一个$embedding$层,把一个物品ID映射到一个向量,记作b,大小跟向量a设置成一样的,向量b是对物品的表征,$embedding$层的参数是一个矩阵,输出的向量b是矩阵的一列,矩阵中列的数量是物品的数量。模型一共用了两个$embedding$层,它们不共享参数,对向量a和b求内积,得到一个实数作为模型的输出,这个模型就是矩阵补充模型,接下来我会解释为什么这个模型叫做矩阵补充。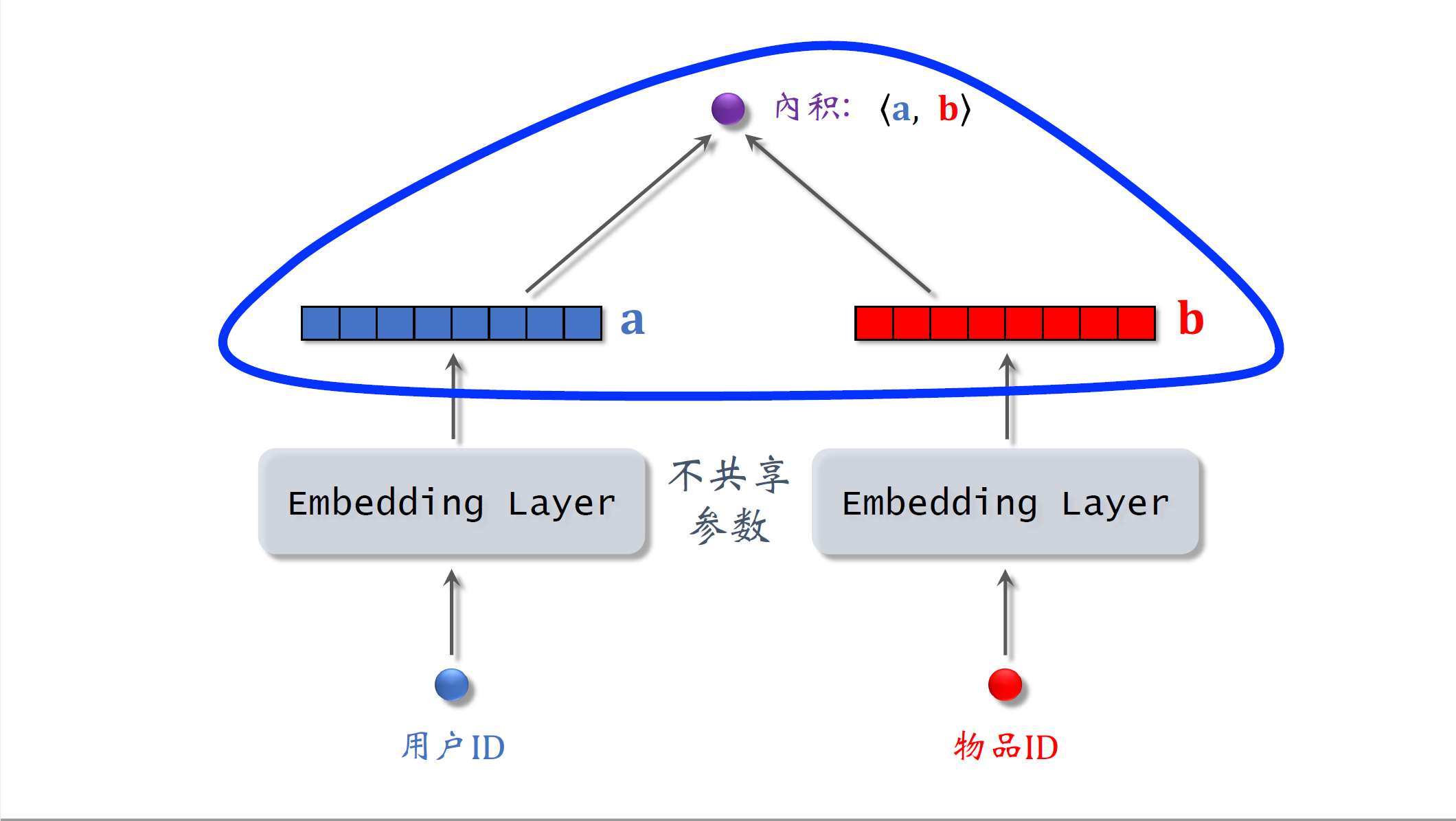
训练
基本思路
刚才定义了模型结构,接下来要讲模型的训练,首先讲训练的基本思路.
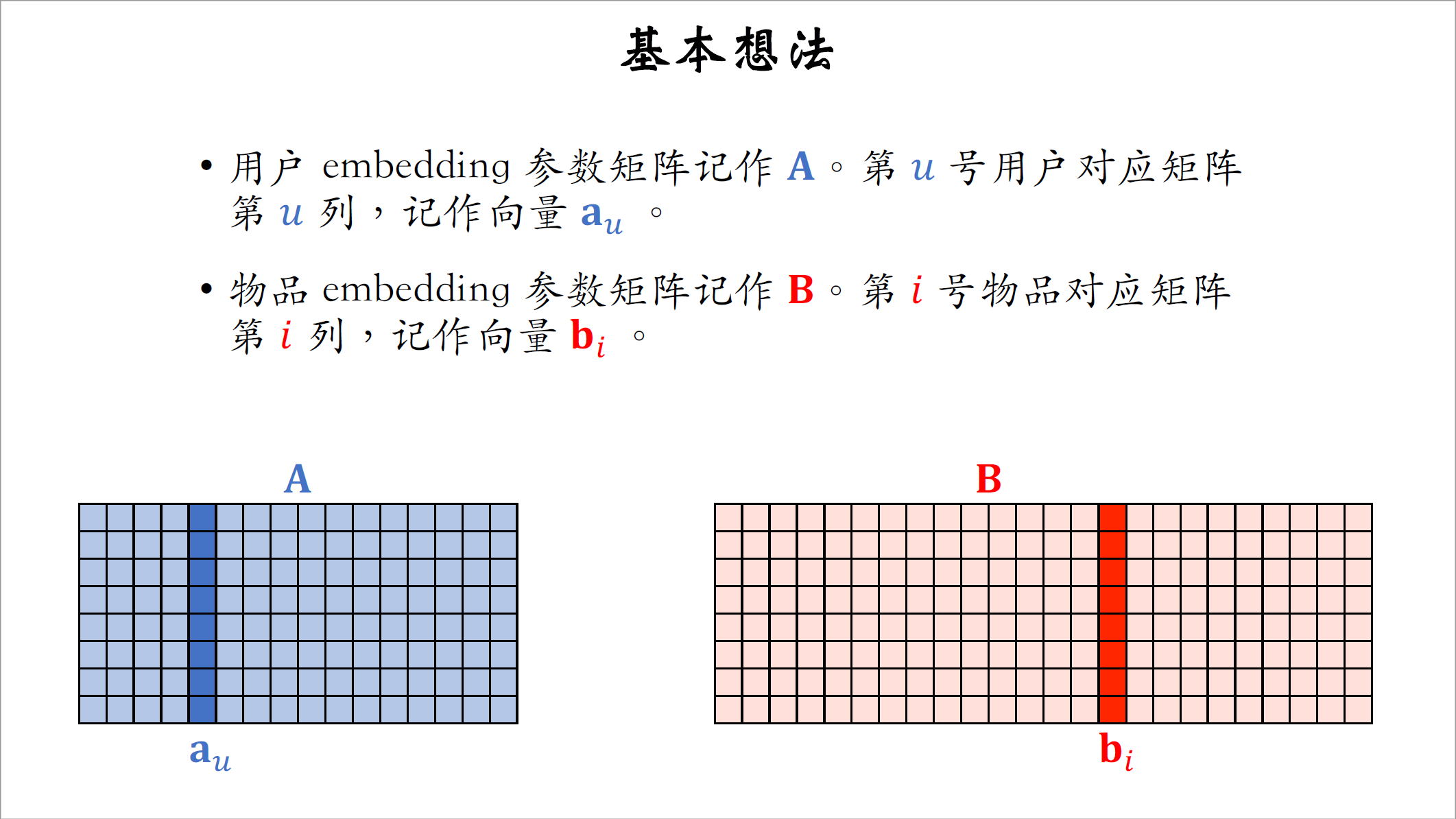
- 用户$embedding$层的参数是一个矩阵,记作$A$,每个用户对应矩阵的一列,第$u$号用户对应矩阵的第$u$列记作向量$a_u$。
- 物品$embedding$层的参数是另一个矩阵,记作$B$,每个物品对应矩阵的一列,第$i$号物品对应矩阵的第$i$列,记作向量$b_i$。
- 向量$a_u$ 和$b_i$ 的内积是第$u$号用户对第$i$号物品兴趣的预估值,内积越大,说明用户u对物品i的兴趣越强。
- 训练模型的目的是学到矩阵$A$和$B$,使得预估值拟和真实观测的兴趣分数,矩阵$A$和$B$是$embedding$层的参数。
数据集
开始训练之前,首先要准备一个数据集,数据集是很多三元组的集合,每个三元组包含用户ID,物品ID,兴趣分数,意思是该用户对该物品真实的兴趣分数在系统里有记录,把数据集记作$\Omega=\{(u,i,y)\}$,$u$和$i$分别是用户ID和物品ID,y是真实观测的兴趣分数。数据集中的兴趣分数是系统记录的。这里举个例子,凡是有曝光的系统都会记录兴趣分数,曝光的意思是把物品展示给用户。如果有曝光,但是没有点击,说明不感兴趣,分数为零;如果有点击、点赞、收藏、转发,这些行为各算一分,这些行为都说明用户对物品感兴趣,那么兴趣分数最低是零分,最高是四分。训练的目的就是让模型的输出拟合兴趣分数。模型中有$embedding$层,可以把用户ID物品ID映射成向量。第$u$号用户映射成向量$a_u$,第$i$号物品映射成向量$b_i$。
训练的时候要求解这样一个优化问题,优化变量是矩阵$A$和$B$,它们是embedding层的参数。
仔细看一下公式,这里的三元组$(u,i,y)$是训练集中的一条数据,意思是用户$u$对物品$i$的真实兴趣分数是$y$。$ < a_u,b_i > $是向量$a_u$和$b_i$的内积,它是模型对兴趣分数的预估反应,第$u$号用户有多喜欢第$i$号物品。$(y- < a_u,b_i > )^2$是真实兴趣分数$y$与预估值之间的差,我们希望这个差越小越好,我们取差的平方,差的平方越小,则预估值越接近真实值$y$。对每一条记录的差的平方求和,作为优化的目标函数,对目标函数求最小化,优化的变量是矩阵$A$和$B$,求最小化可以用随机梯度下降等算法,每次更新矩阵$A$和$B$的一列,这样就可以学出矩阵$A$和$B$。
我来解释一下为什么这个模型叫做矩阵补充,看一下这个矩阵矩阵每一行对应一个用户,每一列对应一个物品,矩阵中的每个元素表示一个用户对一个物品的真实兴趣分数,系统里物品很多,一个用户看过的物品只是系统中的极少数,在矩阵中,绿色位置表示曝光给用户的物品,灰色位置表示没有曝光的物品。只要把物品曝光给用户,我们就知道用户对物品是否感兴趣,曝光了没点击说明不感兴趣,分数是零;曝光之后,用户可能会点击点赞,收藏转发,每个都算一分,加起来最多有四分。比如这个绿色位置表示第3号用户对第2号物品的兴趣分数等于四,矩阵中只有少数位置是绿色,大多数位置都是灰色,也就是没有曝光给用户的,我们并不知道用户对没曝光的物品是否感兴趣。我们刚才拿绿色位置的数据训练出了模型,有了模型,我们就可以预估出所有灰色位置的分数,也就是把矩阵的元素给补全,这就是为什么模型叫做矩阵补充。把矩阵元素补全之后,我们就可以做推荐,给定一个用户,我们选出用户对应的行中分数较高的物品推荐给该用户。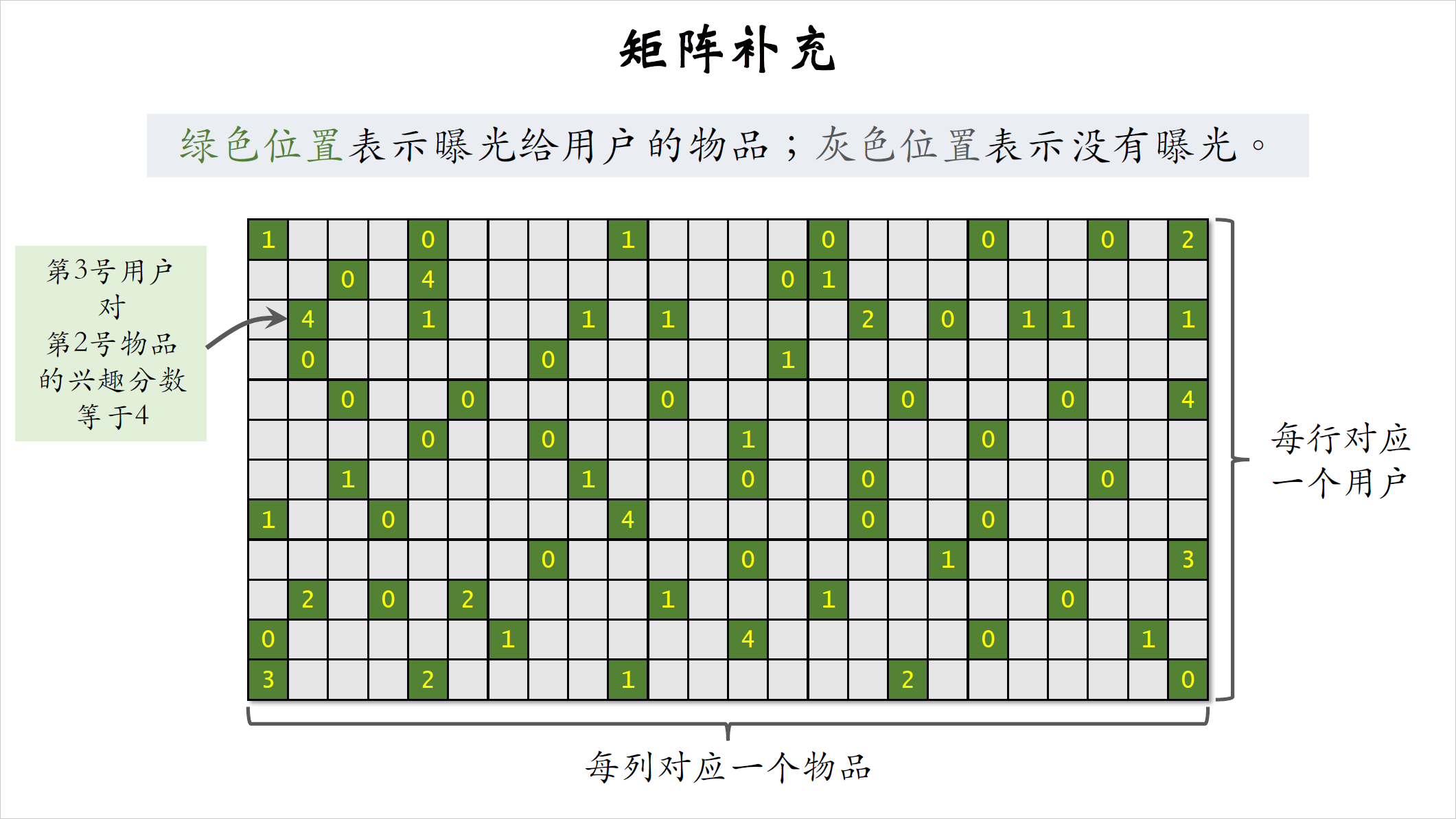
这节课介绍矩阵补充方法只是为了帮助大家理解向量召回而已,矩阵补充并不是工业界能work的方法,在实践中并不会用矩阵补充,我分析一下这种方法的缺点:
- 第一个缺点是矩阵补充没有利用物品属性和用户属性,矩阵补充仅仅用到了ID $embedding$ ,用两个$embedding$层分别把物品ID和用户ID设成两个向量。在小红书的场景下,物品属性包括类目关键词,地理位置,作者信息等等,用户属性包括性别年龄,地理定位,感兴趣的类目。知道这些属性召回可以做得更精准,下节课介绍双塔模型,可以看做矩阵补充模型的升级版,双塔模型不单单使用物品ID和用户ID,还会结合各种物品属性和用户属性,双塔模型的实际表现非常好。
- 矩阵补充的第二个缺点是负样本的选取方式不对。样本指的是用户$u$和物品$i$的二元组,记作$(u,i)$。训练向量召回模型,需要正样本和负样本,矩阵补充的正样本指的是物品给用户曝光之后有点击交互的行为,这样的正样本是ok的,没问题,工业界都这么做,但是负样本的选取方式是完全错误的,矩阵补充的负样本是曝光之后没有点击交互的物品,这是一种想当然的做法,学术界的人可能以为这样没错,但可惜这样在实践中不work。后面我会专门用一节课讲解正负样本怎么选。
- 第三个缺点是训练模型的方法不好,矩阵补充模型用向量$a_u$ 和$b_i$ 的内积作为兴趣分数的预估。这样没错,可以work,但是效果不如余弦相似度,工业界普遍使用余弦相似度,而不是用内积矩阵补充。用平方损失函数,也就是做回归,让预估的兴趣分数拟合真实的兴趣分数,这样做的效果不如交叉熵损失函数也就是做分类,工业界通常做分类,判定一个样本是正样本还是负样本。
线上服务
这节课剩下内容都是线上服务,在训练好模型之后,可以把模型用作推荐系统中的召回通道,比如在用户刷小红书的时候,快速找到这个用户可能感兴趣的一两百篇笔记。
模型存储
做完训练之后,要把模型存储在正确的地方,便于做召回训练,得到矩阵$A$和$B$,他们是embedding层的参数,$A$的每一列对应一个用户,$B$的每一列对应一个物品。线上做推荐的时候,要用到矩阵$A$和$B$,这两个矩阵可能会很大,比如小红书有几亿用户,几亿篇笔记,那么这两个矩阵的列数都是好几亿,为了快速读取和快速查找,需要特殊的存储方式,把矩阵$A$的列存储到一张key-value表,存储的key值是用户的ID,value是矩阵$A$的一列,给定用户ID在表中做查找,得到一个向量,也就是该用户的embedding,另一个矩阵$B$也很大,$B$的存储和索引比较复杂,不能简单的用key-value存储,稍后我会解释原因以及解决方案。

在训练好模型,并且把$embedding$向量做存储之后,可以开始做线上服务。某用户刷小红书的时候,小红书的后台会开始做召回,把这位用户的ID作为key值查询,key-value表,得到该用户的$embedding$向量记作$a$,我们要查找用户最可能感兴趣的k个物品,作为召回结果,这叫做最近邻查找(nearest neighbor search),把第$i$号物品的$embedding$向量记作$b_i$ ,计算用户向量$a$和物品向量$b_i$ 的内积,这是用户对第$i$号物品兴趣分数的预估,返回内积最大的k个物品,比如k等于100,这些物品就是召回的结果。
这种最近邻查找有个严重的问题,如果逐一对比所有物品时间复杂度会正比于物品数量,这种巨大的计算量是不可接受的,比如小红书有几亿篇笔记,那么就有几亿个向量$b$,逐一计算向量$a$和每个向量$b$的内积是不现实的,根本做不到线上的实时计算,这节课剩下的内容就是如何加速最近邻查找,避免暴力枚举。
近似最近邻查找(Approximate Nearest Neighbor Search)
有很多算法加速最近邻查找,这些算法非常快,即使有几亿个物品,最多也只需要几万次内积,这些算法的结果未必是最优的,但是不会比最优结果差多少。
快速最近邻查找的算法已经被集成到很多向量数据库系统中,比较有名的包括Milvus、Faiss、HnswLib,做最近邻查找,需要定义什么是最近邻,也就是衡量最近邻的标准,比如最近邻可以定义为欧式距离最小的最近,你也可以定义为向量内积最大的,这叫做内积相似度,这节课的矩阵补充用的就是内积相似度,目前推荐系统最常用的是余弦相似度,其最近邻是向量夹角最小的,有些系统不支持余弦相似度,但这很好解决,如果你把所有向量都做归一化,让他们的二范数全都等于一,那么内积就等于余弦相似度。
我用一个直观的例子来演示最近邻查找。这是个散点图,每个点是一个物品的$embedding$向量,$embedding$向量都是训练模型的时候计算出来的,右边的五角星表示一个用户的$embedding$向量记作a,我们想要召回这个用户可能感兴趣的物品,这就需要计算向量a与所有点的相似度,如果用暴力枚举的话,计算量正比于点的数量,也就是物品的数量,想要减少最近邻查找的计算量,必须要避免暴力枚举。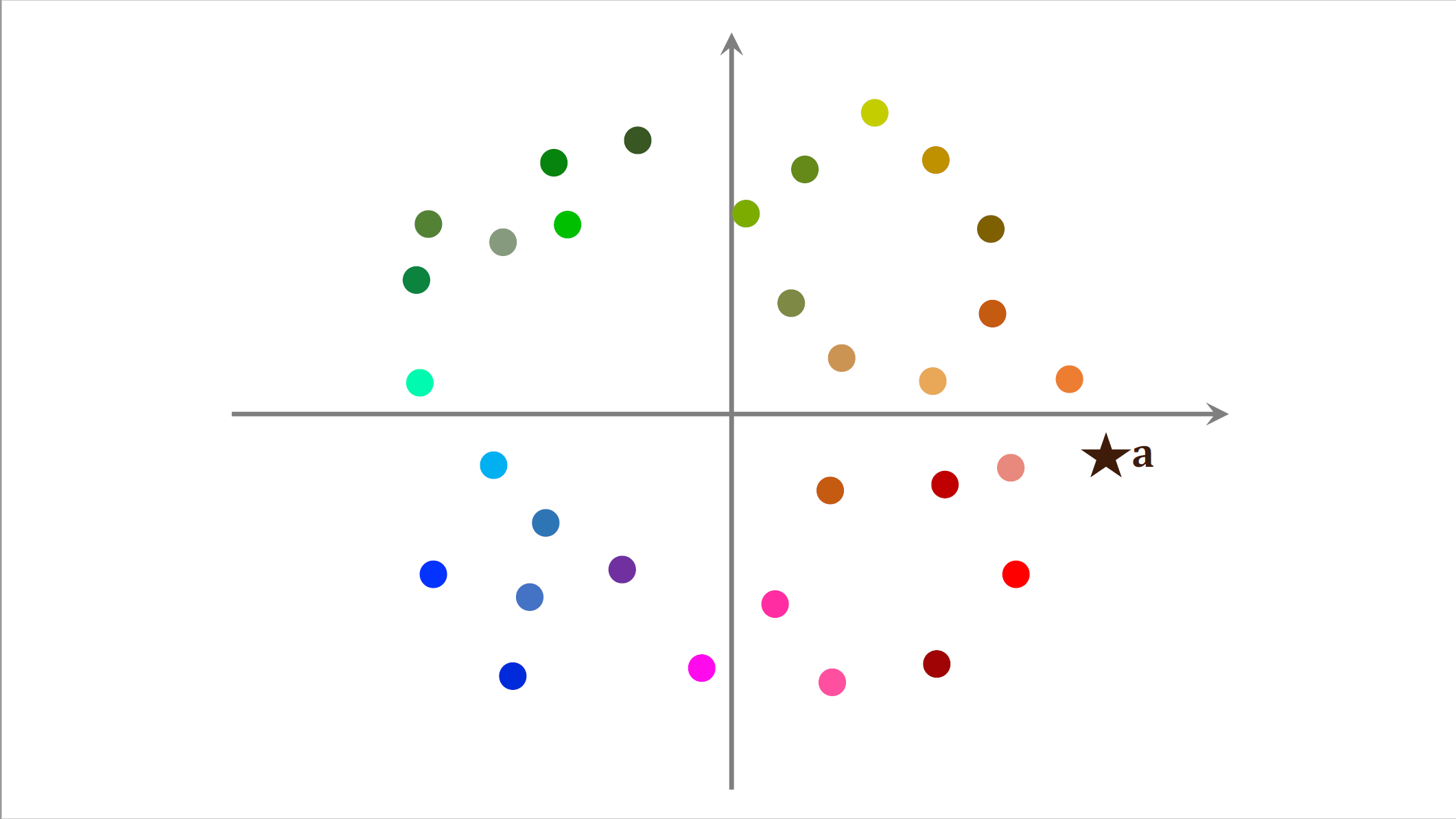
这里介绍一种加速最近邻查找的办法,在做线上服务之前,先对数据做预处理,把数据划分成很多区域,比如这样划分,至于如何划分,取决于衡量最近邻的标准,如果是cos相似度,那么划分的结果就是这样的扇形,如果是用欧式距离,那么划分的结果就是多边形。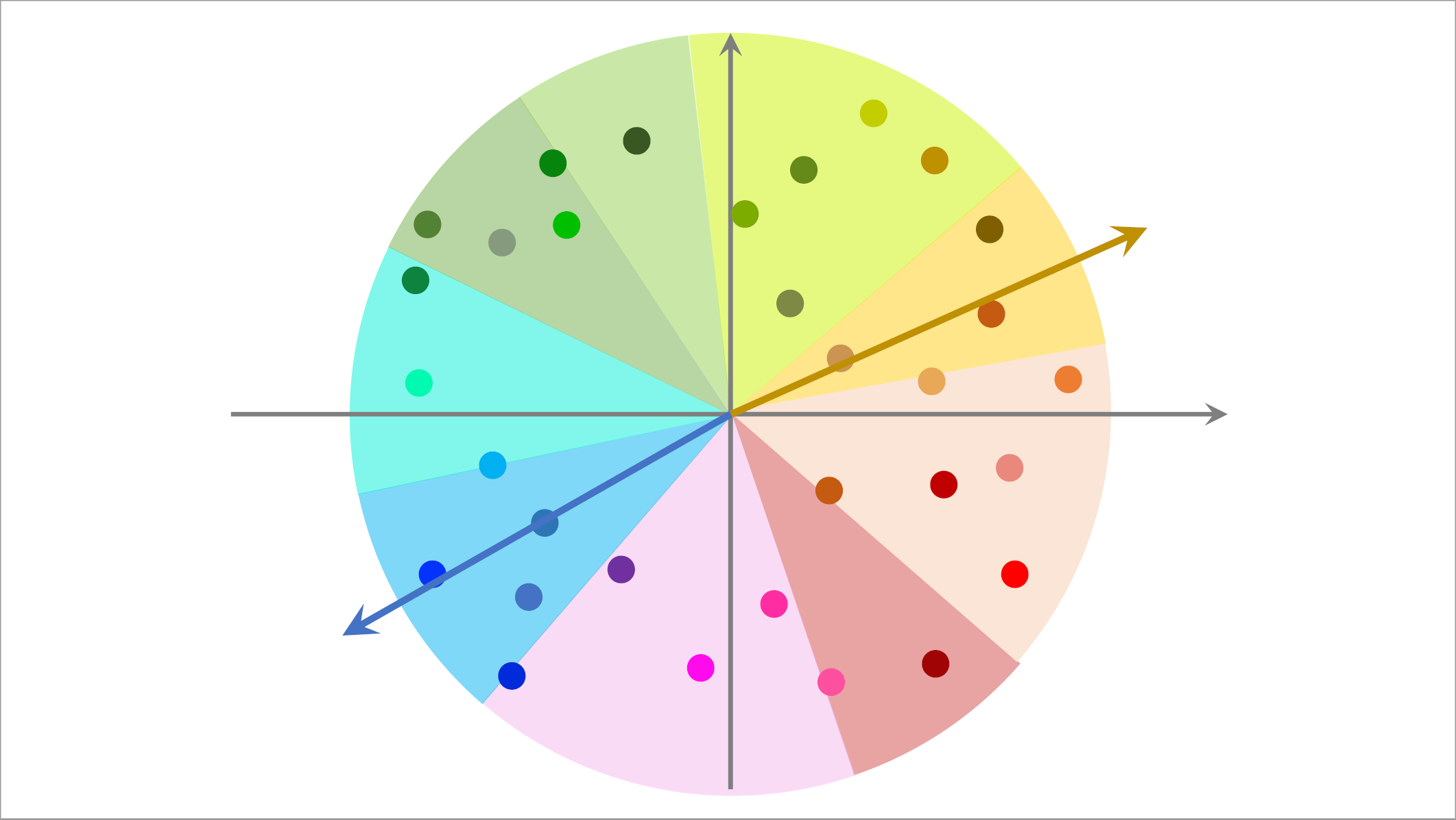
划分之后,每个区域用一个向量表示,比如这个蓝色区域用这个向量表示,比如这个黄色区域用这个向量表示,这些向量的长度都是一。划分区域之后建立索引,把每个区域的向量作为key,把区域中所有点的列表作为value,给定蓝色这个向量就能取回蓝色扇形区域中的所有的点。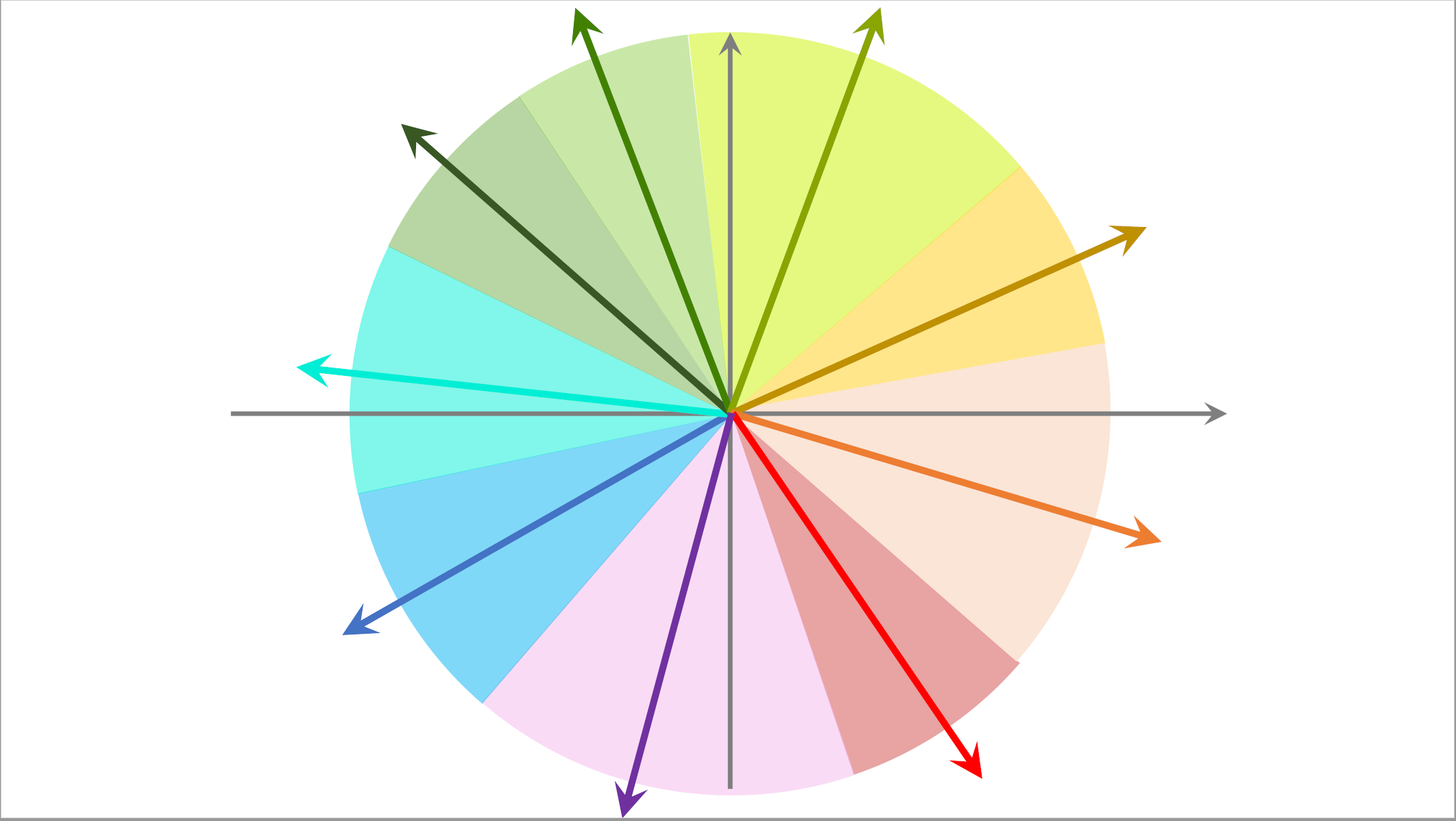
划分区域之后,每个区域都用一个单位向量来表示,假如有一亿个点,那么划分成1万个区域,索引上一共有1万个k值,每个向量是一个区域的k值,给定一个向量可以快速取回这个区域内所有的点,有了这样一个索引就可以在线上快速做召回了。在线上给一个用户做推荐,这个用户的$embedding$向量记作$a$,我们首先把向量$a$跟索引中这些向量做对比,计算它们的相似度。如果物品数量是几亿,索引中的向量数量也只有几万而已,这一步的计算开销不大,计算相似度之后,我们发现索引中这个向量与$a$最相似,通过索引我们找到这个区域内所有的点,每个点对应一个物品。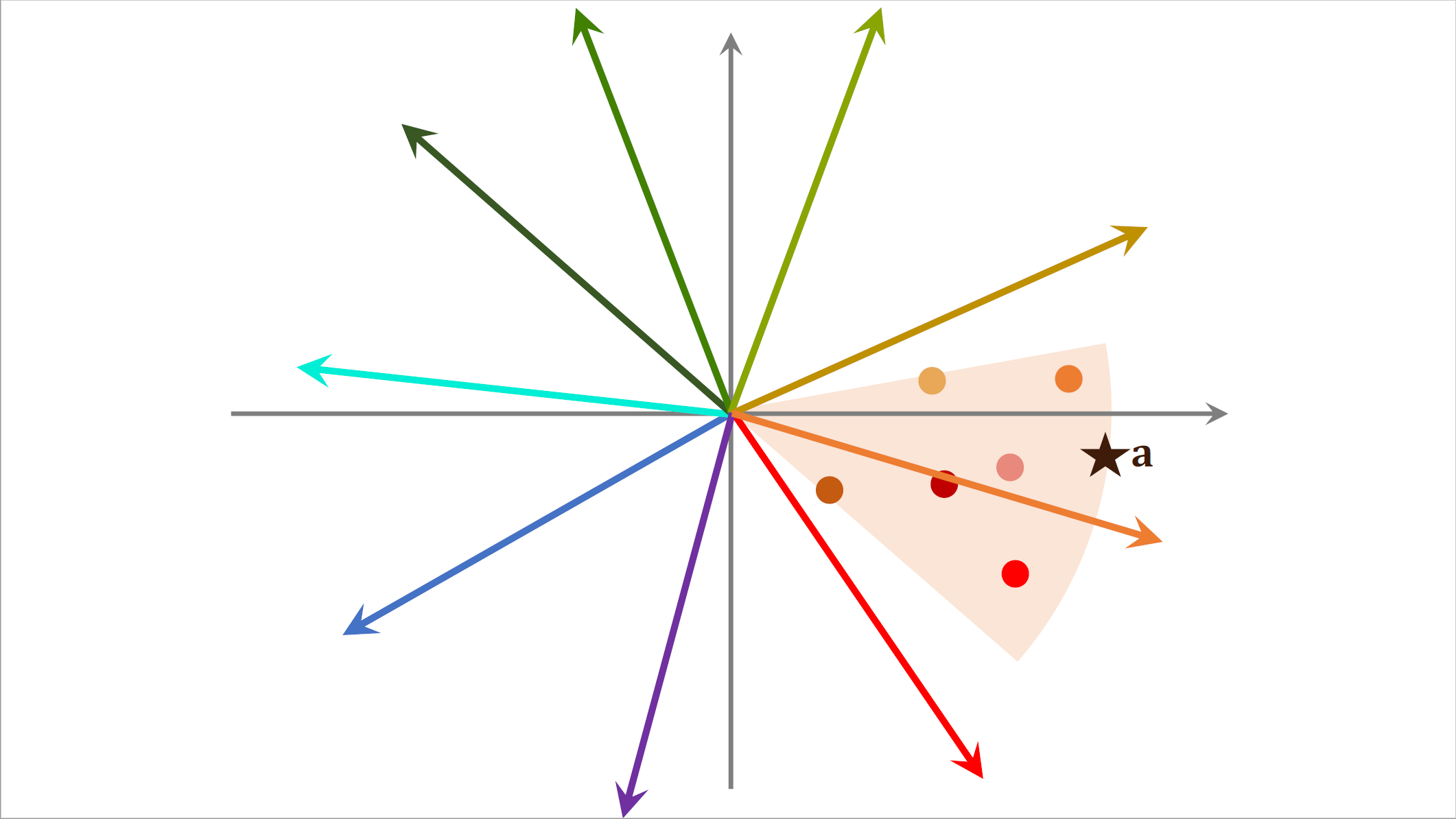 接下来我们计算点$a$跟区域内所有点的相似度,如果一共有几亿个物品被划分到了几万个区域,平均每个区域只有几万个点,所以这一步只需要计算几万次相似度,计算量也不大。假如我们想要找向量$a$最相似的三个点,也就是夹角最小的三个点,那么会找到这三个点,对应三个物品。这三个物品就是最近邻查找的结果,哪怕有几亿个物品,用这种近似算法做查找,也只需要计算几万次相似度,比暴力枚举快1万倍。
接下来我们计算点$a$跟区域内所有点的相似度,如果一共有几亿个物品被划分到了几万个区域,平均每个区域只有几万个点,所以这一步只需要计算几万次相似度,计算量也不大。假如我们想要找向量$a$最相似的三个点,也就是夹角最小的三个点,那么会找到这三个点,对应三个物品。这三个物品就是最近邻查找的结果,哪怕有几亿个物品,用这种近似算法做查找,也只需要计算几万次相似度,比暴力枚举快1万倍。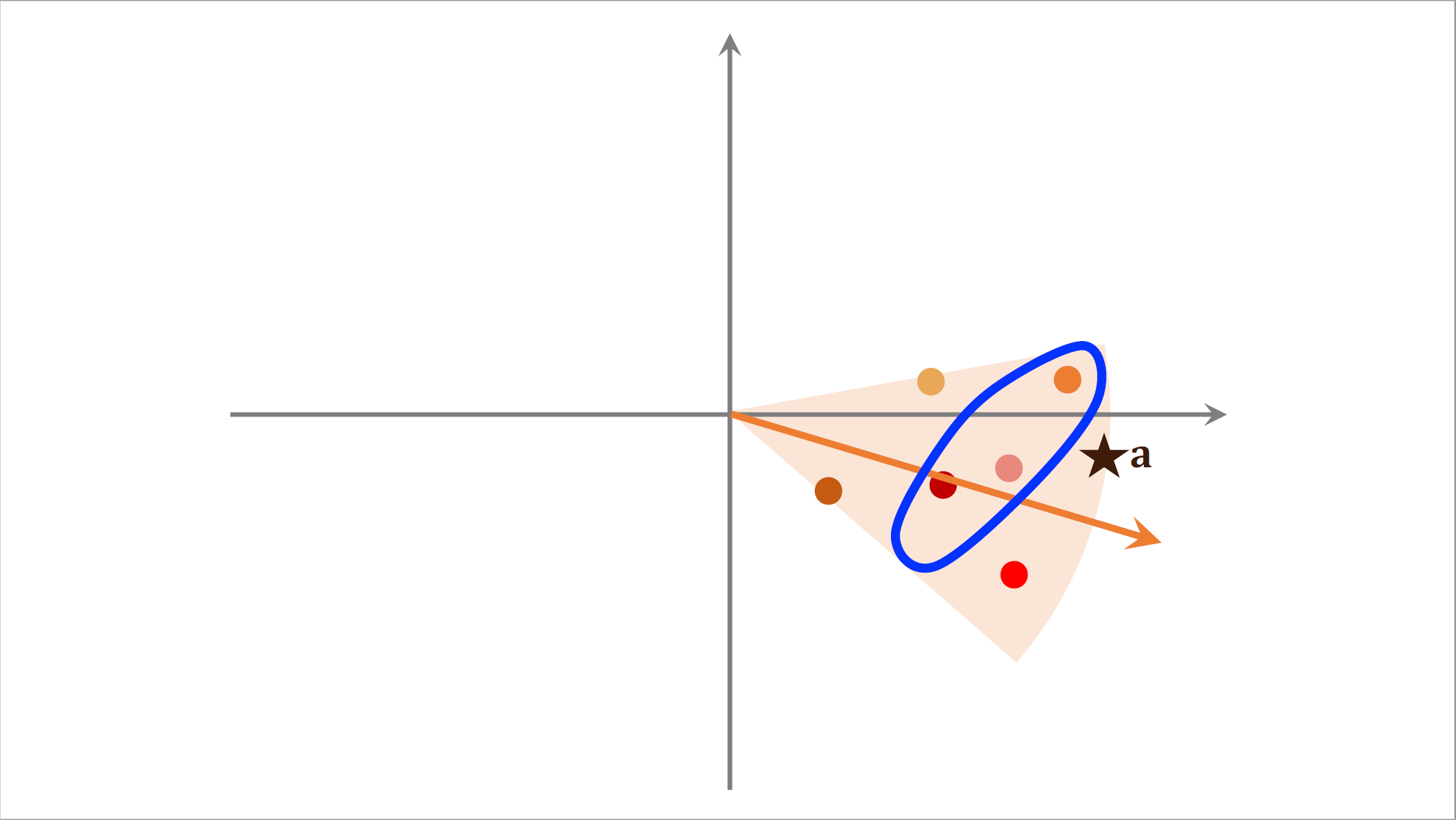
总结
最后总结一下这节课的内容,这节课主要介绍了矩阵补充模型,矩阵补充的想法是把物品ID和用户ID做embedding映射成两个向量,两个向量记作$a_u$和$b_i$。两者内积作为用户$u$对物品$i$兴趣的预估值。训练的时候,我们让$a_u$和$b_i$的内积拟合真实观测到的兴趣分数,用回归的方式学习模型中$embedding$层的参数。
矩阵补充是个学术界的模型,有很多缺点导致效果不好,工业界其实不用矩阵补充模型,而是用更先进的双塔模型。
假如用矩阵补充在线上做召回也是可以的,尽管效果不好,把用户向量$a$作为query,查找使得向量$a$和$b_i$内积最大化的物品$i$,寻找这样内积最大的top k物品$i$作为召回的结果。在工业界的场景下,有上亿物品,做暴力枚举的速度太慢了,不可行,实践中都用近似最近邻查找,不需要做枚举,我已经讲了近似最近邻查找的做法,工业界通常会用一些开源的向量数据库,比如Milvus、Faiss、HnswLib,这些向量数据库都会支持近似最近邻查找。
这节课就讲到这里,感谢大家观看,下节课讲双塔模型。