
召回07:双塔模型——正负样本
本博文引自王树森老师推荐系统。
视频地址:召回07:双塔模型——正负样本_哔哩哔哩_bilibili
课件地址: https://github.com/wangshusen/RecommenderSystem
这节课继续讲双塔模型,训练双塔模型需要用到正样本和负样本,选对正负样本作用大于改进模型结构。
正负样本
正样本
首先来讨论如何选择正样本,正样本比较好选,如果物品给用户曝光之后,用户有点击行为,就说明用户对物品感兴趣,把用户和物品二元组作为正样本。
但是选取正样本的时候,有个问题需要解决,大家应该听说过二八法则,就是少部分物品占据了大部分点击,正样本是有点击的物品,所以正样本大多属于热门物品,拿过多的热门物品作为正样本,会对冷门物品不公平,这样会让热门物品更热,冷门物品更冷,解决方案是对冷门物品做过采样,或者对热门物品做降采样,过采样的英文是up-sampling,意思是让一个样本出现多次,降采样的英文是down-sampling,意思是抛弃一些样本,比如以一定概率抛弃热门物品,抛弃的概率与样本点击次数正相关。
前面的课程讲过推荐系统的链路分为召回,粗排,精排,重排,稍后要用到。这里再简单回顾一下,召回是从物品的数据库中快速取回一些物品,比如小红书有上亿篇笔记,就用几十条召回通道各取回一两百篇笔记,一共取回几千篇笔记;然后用粗排和精排给召回的笔记逐一打分,保留分数最高的笔记;最后一步是重排,这一步主要是做多样性采样,还会用很多规则做调整,最终有几十篇笔记被选中曝光给用户。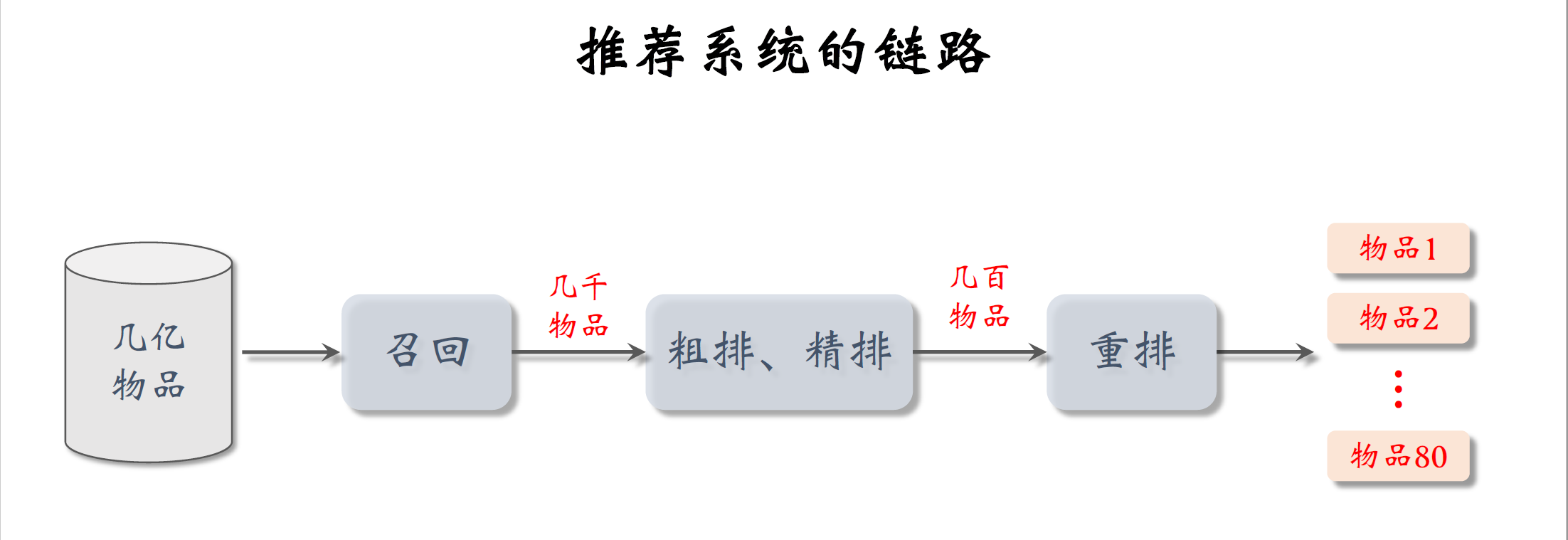
负样本
下面我们讨论怎样选取训练双塔模型的负样本,负样本就是用户不感兴趣的物品,也就是链路上每一步被淘汰的物品,召回模块从几亿个物品中选出几千个,被召回的物品只是极少数,这些没被召回的几亿个物品可以看作是负样本。粗排和精排,从几千个召回的物品中选出几百个,也就是说几千个物品会被这一步淘汰,最终有几十个物品曝光给用户,但不是每个曝光的物品都会被点击曝光了,但是用户没有点击的,也可以视作是负样本。接下来我们分别讨论这三类负样本。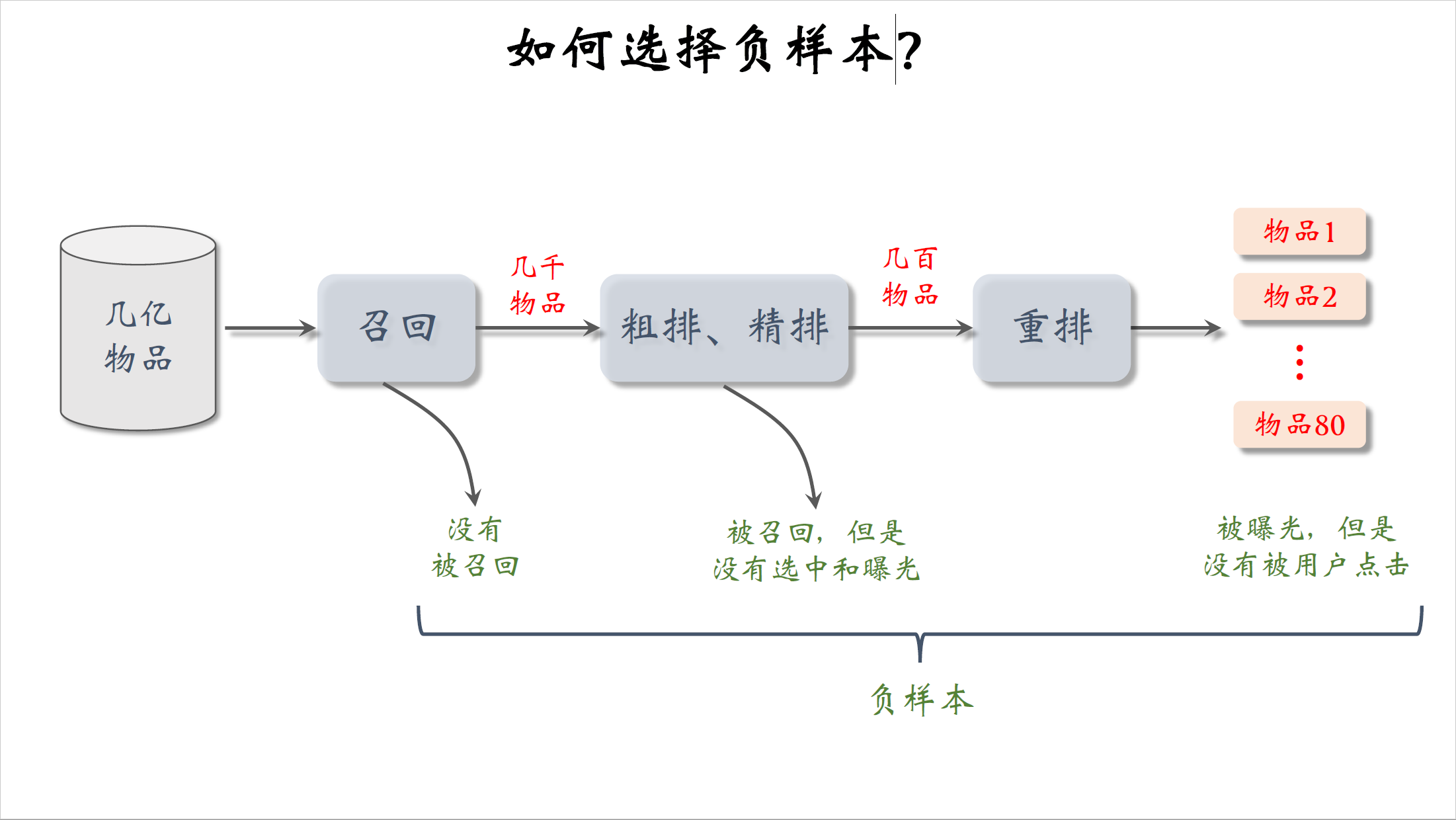
简单负样本
全体物品
首先是简单负样本,简单负样本是未被召回的物品,这种物品通常是用户不感兴趣的,几亿个物品里面只有几千个被召回,也就是说几乎所有的物品都没有被召回,那么未被召回的物品跟全体物品基本上是一回事儿,所以直接在全体物品中做随机抽样就可以了,抽到的物品作为负样本。
问题在于怎样做抽样,是均匀抽样还是非均匀抽样。
均匀抽样的坏处是对冷门物品不公平,前面讨论过二八法则,少部分物品占据了大部分点击,这会导致正样本大多是热门物品。如果在全体笔记中做均匀抽样生成负样本,那么负样本大多是冷门物品,总拿热门物品做正样本,冷门物品做负样本,对冷门物品会不公平,这样会让热门物品更热,冷门物品更冷。所以负样本抽样要随机非均匀,这样可以打压热门物品,抽样的概率与热门程度正相关,热门物品成为负样本的概率大,物品的热门程度可以用它的点击次数来衡量。可以这样做抽样,每个物品的抽样概率正比于它点击次数的0.75次方,0.75是个经验值。
Batch内负样本
刚才介绍的简单负样本是从全体物品中抽的,下面我介绍另一种简单负样本叫做Batch内负样本。图中是一个batch的样本,左边是用户,右边是物品,中间的箭头表示用户点击过的物品。图中任意一个样本都是正样本,比方说第二个用户点击过第二个物品,这就说明用户对物品感兴趣,这个二元组是个正样本。
什么是batch内负样本呢?这里举个例子,第一个用户跟第二个物品可以组成一个负样本,第一个用户跟第三个物品也可以组成一个负样本。设一个batch内有n个正样本,那么一个用户跟n-1个物品可以组成负样本,所以这个batch内一共有n(n-1)个负样本。这些都属于简单负样本,对于第一个用户来说,第二个物品就相当于是从全体物品中随机抽样的,第一个用户大概率不会喜欢第二个物品。
batch内负样本存在一个问题,我来分析一下。图中这些二元组都是通过点击行为选取的,第一个用户和第一个物品之所以成为一个正样本,原因是用户点击了物品,所以一个物品出现在batch内的概率正比于它的点击次数,也就是它的热门程度。这样就会有个问题,前面讨论了,物品成为简单负样本的概率应该是正比于点击次数的0.75次方,但是在这里我们做batch内负采样,物品成为负样本的概率正比它点击次数的一次方。
重复一遍,抽样概率本应该正比于点击次数的0.75次方,但这里实际上是一次方,也就是说热门物品成为负样本的概率过大,一个物品成为负样本的概率越大,模型对这个物品打压就会越狠。对负样本应该打压,但这里打压的太狠了,这样会造成偏差。下面这篇Youtube论文,我们在小红书照着做了,确实拿到了收益,我具体讲一下如何修正偏差。
我们把物品$i$被抽到的概率记作$p_i$,它正比于物品$i$的点击次数,反映出物品的热门程度,双塔模型通常用余弦相似度预估用户对物品$i$的兴趣分数。cos中的$a$是用户的特征向量,$b_i$是物品$i$的特征向量。训练的时候要鼓励正样本的余弦相似度尽量大,鼓励负样本的余弦相似度尽量小。根据youtube论文的建议,训练双塔模型的时候,应该把$\cos(a,b_i)$调整为$\cos(a,b_i)- \log p_i$,这样可以纠偏,避免过分打压热门的物品。训练结束之后,在线上做召回的时候,还是用原本的余弦相似度$\cos(a,b_i)$,线上召回的时候不用做这种调整,不用剪掉$\log p_i$。
困难负样本
刚才我讲了两种简单负样本,一种是从全体物品中做随机抽样生成负样本,另一种是在batch内生成负样本,接下来我要介绍困难负样本。
困难负样本是被排序淘汰的物品,比如物品被召回,但是被粗排淘汰,比方说召回5000个物品进入粗排,粗排按照分数做截断,只保留前500个,那么被淘汰的4500个物品都可以被视作负样本。为什么被粗排淘汰的物品叫做困难负样本呢,这些物品被召回,说明他们跟用户兴趣多少有些关系,被粗排淘汰,说明用户对物品的兴趣不够强,所以分成了负样本,对正负样本做二元分类的话,这些困难负样本容易被分错,容易被错误地判定为正样本。
更困难的样本是通过了粗排,但是在精排中分数排名靠后的物品,比方说精排给500物品打分,排名在后300多物品都算是负样本。能够通过粗排进入精排,说明物品已经比较符合用户兴趣了,但未必是用户最感兴趣的,所以在精排中排名靠后的物品可以被视为负样本。
训练双塔模型其实是个二元分类任务,让模型区分正负样本,把全体物品作为简单负样本,分类准确率会很高,因为他们明显跟用户兴趣不符,被粗排淘汰的物品也是负样本,但他们多少跟用户兴趣有些相关,所以比较困难,分类准确率会稍微低一些。精排分数靠后的物品也可以视作是负样本,这些物品跟正样本有些相似,所以他们很容易被判定为正样本,对他们做分类非常困难。
训练数据
工业界比较常用的做法是,把简单负样本与困难负样本混合起来作为训练数据,比如50%是简单副样本,就是从全体物品中随机非均匀抽样出来的,另外50%是困难负样本,也就是从粗排和精排淘汰的物品中随机抽样出来的。
常见错误
前面解释了简单负样本和困难负样本,最后讨论一种常见的错误。
很多人以为可以把曝光但是没有点击的物品作为负样本,其实这是错误的,如果你训练双塔模型的时候,用一些这样的负样本,效果肯定会变差,工业界的人已经踩过这个雷,把这个作为教训。我再解释一遍,这种错误的负样本是什么意思,看一下这张图,这些都是重排之后曝光给用户的物品。通过一些技术手段,我们得知用户只看了前五个物品,也就是说前五个物品曝光给了用户,第6~80物品没有曝光,在曝光的物品里面,第一个和第五个被用户点击,其余三个物品没有被用户点击。有人觉得可以把这三个物品当做负样本,因为他们有曝光,但是没有点击。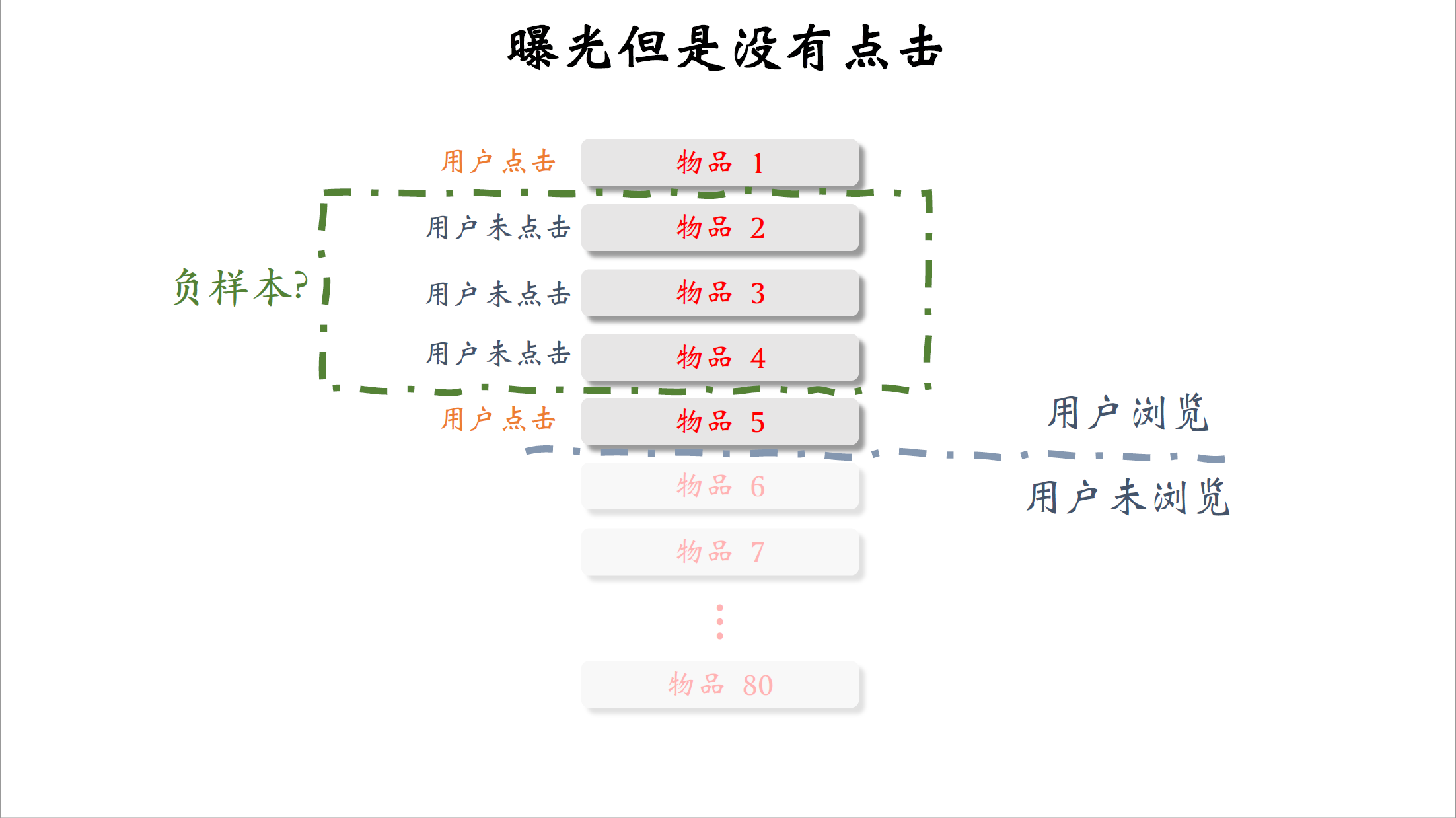
我再强调一遍,这种想法是错误的,训练召回模型不能用这样的负样本,原因,我稍后解释。这种负样本不是给训练召回模型用的,而是给训练排序模型用的,训练排序模型的时候确实要用这种曝光,但是没有点击的物品作为负样本。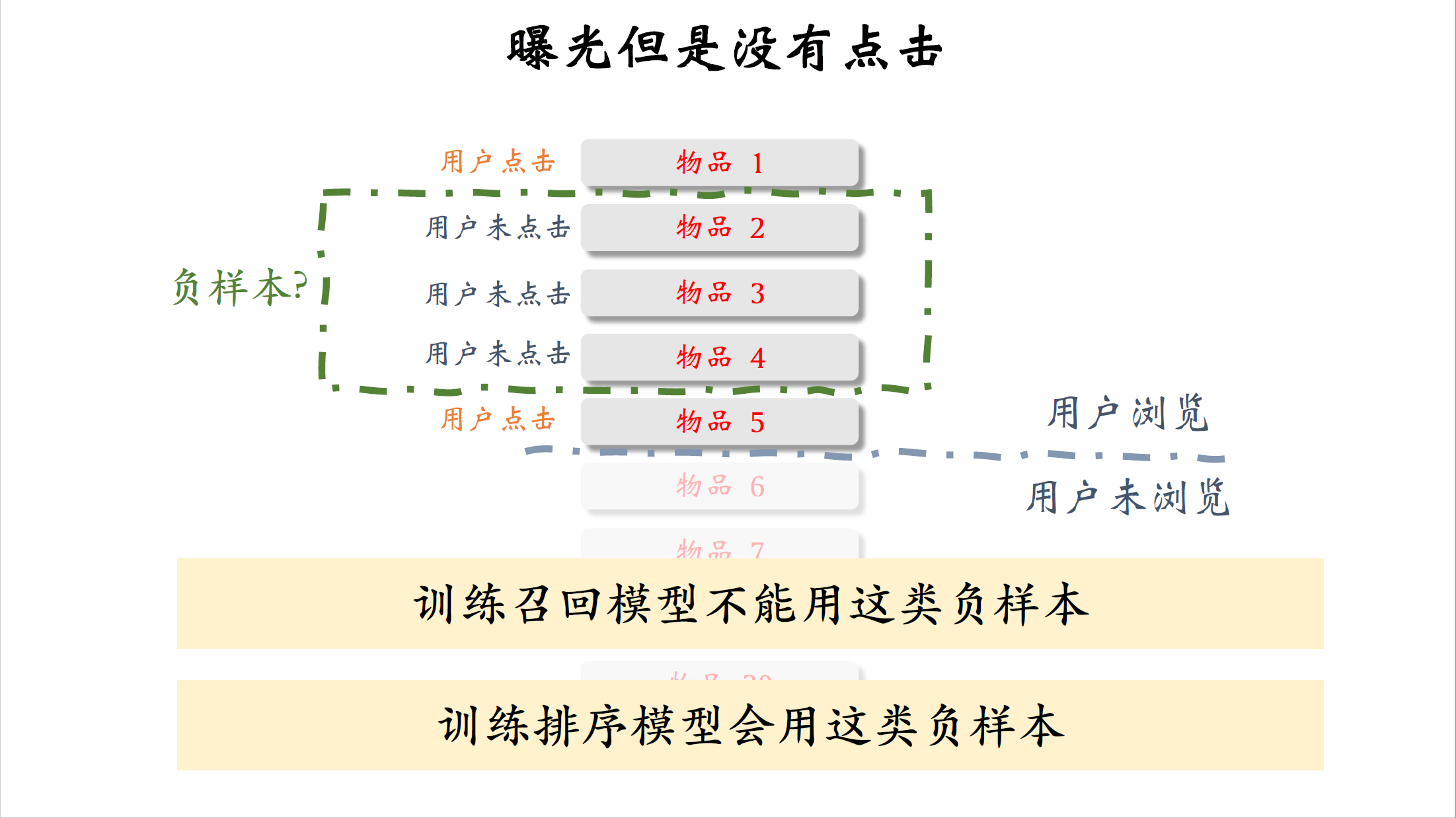
我解释一下选择负样本的原理,召回的目的是快速找到用户可能感兴趣的物品,凡是用户可能感兴趣的全都取回来,然后再交给后面的排序模型逐一做甄别。召回模型的任务是区分用户不感兴趣的物品和可能感兴趣的物品,而不是区分比较感兴趣的物品和非常感兴趣的物品,这就是选择负样本的基本思路。
可以把全体物品当做负样本,把它们叫做简单负样本,这些物品绝大多数都是用户根本不感兴趣的,双塔模型很容易区分这些负样本。
被召回,然后被粗排精排淘汰的叫做困难负样本,这些物品能被召回,说明他们跟用户的兴趣有一定的相关性,被排序模型过滤掉,说明用户对这些物品的兴趣不够强,它们可以作为负样本。这样的负样本跟正样本有点像,做分类的时候比较难以区分,所以算是困难负样本。
有曝光,但是没有点击的物品,看起来可以作为负样本,但其实不能,只要用了这种负样本,双塔模型的效果肯定会变差。为什么呢?一个物品能够通过精排模型的甄别,最终曝光给用户,说明物品已经非常匹配用户的兴趣点了。每次给用户展示几十个物品,用户不可能每个物品都点击,没有点击不代表不感兴趣,可能只是用户对别的物品更感兴趣,就点击了别的,或者是用户感兴趣,只是碰巧没有点击。曝光但是没有点击的物品已经算是非常匹配了,甚至可以拿来做召回的正样本,不应该把曝光但是没有点击的物品作为召回的负样本。记住这一点,召回的目的是区分不感兴趣的和比较感兴趣的,而排序才是区分比较感兴趣的和非常感兴趣的。这类负样本只适用于训练排序模型,但不适用于训练召回模型,这是工业界的共识,是通过反复做实验得出的结论。
总结
最后总结一下这节课的内容,这节课详细讲解了如何选择正负样本:
- 正样本意思是曝光而且有点击的用户物品二元组。
- 简单负样本有两种,一种是从全体物品中做随机抽样,另一种是batch内负样本。
- 困难负样本是被召回,但是被排序淘汰的物品,这些物品跟正样本比较像,做分类会有困难,所以叫做困难负样本。
- 我们还讨论了一种错误的做法,就是拿曝光但是未点击的物品作为召回的负样本,这种负样本只能用于排序,不能用于召回。
