
召回08:双塔模型——线上服务、模型更新
本博文引自王树森老师推荐系统。
视频地址:召回08:双塔模型——线上服务、模型更新_哔哩哔哩_bilibili
课件地址: https://github.com/wangshusen/RecommenderSystem
这节课我们继续学习双塔模型,这节课内容是双塔模型的线上召回和更新。
线上召回
在训练好双塔模型之后,就可以把模型部署到线上做召回。比如在用户刷小红书的时候,快速找到这个用户可能感兴趣的一两百篇笔记,下面的内容就是双塔模型怎样做召回。
这是训练好的两个塔,它们分别提取用户特征和物品特征。在训练好模型之后,在开始线上服务之前,先用右边的物品塔提取物品的特征,把物品特征向量记作$b$。小红书有几亿篇笔记,那么就得到几亿个向量$b$,把物品特征向量,物品ID这样的二元组保存到Milvus、Faiss这样的向量数据库。
这些是物品的特征向量和对应的ID,有几亿个物品,所以有几亿个特征向量,向量数据库存储特征向量和物品ID的二元组,用作最近邻查找。前面的课介绍过如何快速做最近邻查找。
至于左边的用户塔处理方式完全不一样,不要事先计算和存储用户向量,而是当用户发起推荐请求的时候,调用神经网络在线上现算一个特征向量$a$,然后把向量$a$作为query去数据库中做检索,查找最近邻,也就是跟向量$a$相似度最高的k个红色向量。每个红色向量对应一篇笔记,K近邻查找一共召回了K篇笔记,作为这条召回通道的结果返回。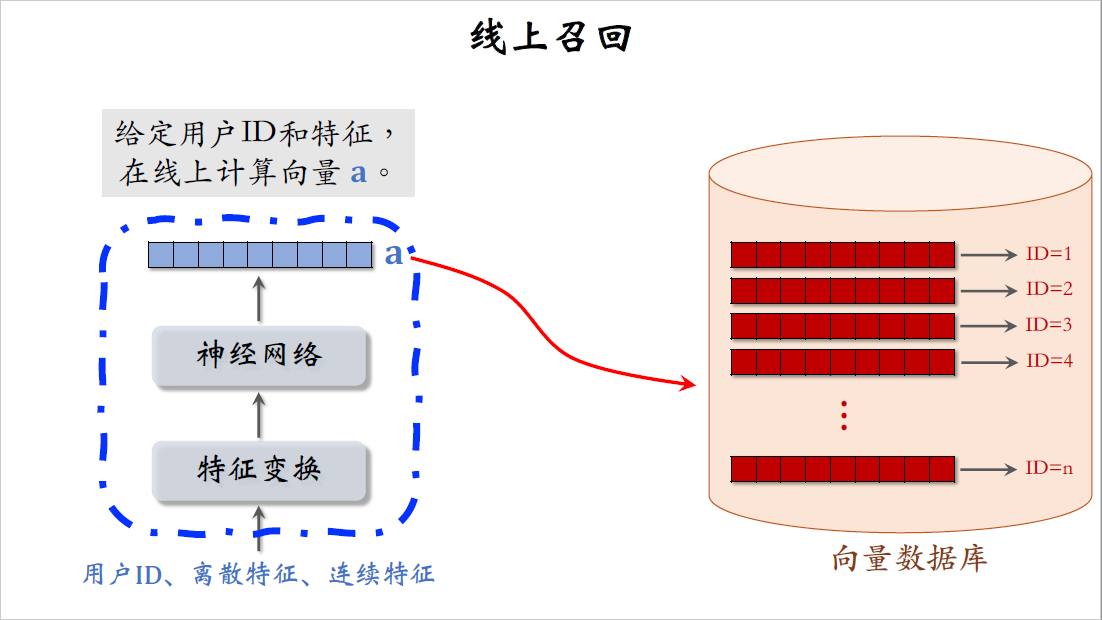
我已经讲完了双塔模型的召回,我再总结一遍:
- 训练好双塔模型之后,在开始线上服务之前先要做离线存储,用神经网络计算每个物品的特征向量$b$,把这几亿个物品向量存入向量数据库,比如Milvus、Faiss、HnswLib这样的开源系统。
向量数据库会建立索引,前面的课程讲过,建索引就是把向量空间划分成很多区域,每个区域用一个向量表示,这样可以加速最近邻查找,在向量数据库建好索引之后,可以开始做线上召回。比如一个用户刷小红书的时候,双塔模型的召回通道可以返回用户可能感兴趣的k个物品。

用户发起推荐请求,我们知道用户ID和用户画像,把这些信息输入用户塔神经网络,算出用户向量$a$,然后在向量数据库中做最近邻查找,把用户的特征向量$a$作为query,调用Milvus、Faiss这种向量数据库做近似最近邻查找。
- 数据库返回预先相似度最大的k个物品,作为召回的结果,接下来这些物品会跟ItemCF、Swing、UserCF等召回通道的结果融合,然后经过排序,最终展示给用户.

我已经讲完了召回的内容,请大家思考一个问题,在开始线上召回之前,我们先要把物品向量$b$存储到向量数据库,但是我们不存储用户向量$a$,而是在线上用神经网络现算用户向量$a$,为什么要区别对待物品向量和用户向量呢?
道理是这样的,每做一次召回只用到一个用户向量$a$,而要用到几亿个物品向量$b$,拿神经网络现算一个用户向量,计算量不大,算得起,但是几亿个物品向量显然是算不起的,所以我们不得不离线算好物品向量。
那么能不能把几亿个用户向量也事先算好,把几亿个向量存储起来,进一步减少线上的计算负担呢,这样做当然可以,推荐团队早期技术很弱的时候,通常会这样做,这样工程实现很简单,但这样不利于推荐的效果,用户的兴趣点是动态变化的,所以应该在线上实时计算用户向量,而不是事先计算好,存起来。
事先存储用户向量,效果不好,但事先存储物品向量是OK的,这是因为物品的特征相对比较稳定,短期内不会发生变化。
模型更新
刚才介绍了线上召回,在实践中还会更复杂一些,会涉及到模型的全量更新和增量更新。
全量更新,意思是在每天凌晨用前一天的数据训练模型,比方说在今天凌晨就用昨天的数据训练模型,注意是在昨天模型参数的基础上做训练,而不是重新随机初始化。把昨天一天的数据打包成TFRecord文件,在昨天模型参数的基础上做训练,把昨天的数据过一遍,每条数据只用一次,也就是训练只做one epoch。
训练完成之后,发布新的用户塔神经网络,用户塔的作用是在线上实时计算用户向量,作为召回的query,还要发布新的物品向量,这几亿个向量存入向量数据库,向量数据库会重新建索引,然后可以在线上做最近邻查找。全量更新的实现相对比较容易,对数据流和整个系统的要求不高。全量更新不需要实时的数据流,对生成训练数据的速度没有要求,延迟一两个小时也没有关系,只需要把每天的数据落表,在凌晨做个批处理,把数据打包成TFRecord格式的文件就可以了。全量更新对系统的要求也很低,每天做一次全量更新,所以只需要把神经网络和物品向量,每天发布一次就够了。
与全量更新相对的是增量更新,也就是做online learning更新模型参数,每隔几十分钟就把新的模型参数给发布出去。
为什么要做增量更新呢?这是因为用户的兴趣随时会发生变化。举个例子,我早上刷小红书的时候,看到几篇有意思的笔记,也就是说我产生了新的兴趣点,我在中午刷新小红书,小红书能不能根据我新的兴趣点做推荐呢?如果模型是做天级别的全量更新,肯定是不行的,想要让模型在用户行为发生几小时之内就做出反应,模型需要做到小时级别的增量更新。增量更新对数据流的要求很高,需要实时收集线上的数据,并且对数据做流式处理,实时生成训练模型用的TFRecord文件,然后对模型做online learning,做梯度下降更新ID embedding的参数,也就是说从早到晚训练数据文件不断生成,不断做梯度下降更新模型的embedding层。注意,online learning不更新神经网络其他部分的参数,全连接层的参数都是锁住的,不做增量更新,只更新embedding层的参数,只有做全量更新的时候才会更新全连接层。
至于为什么只更新embedding层参数,不更新全连接层参数,主要是出于工程实践的考量,道理一两句话也解释不清楚。
对模型更新之后,要把算出的用户ID embedding给发布出去,用户ID embedding是一个哈希表的形式,给定用户ID可以查出ID embedding向量。发布用户ID embedding的目的是为了线上计算用户的特征向量,最新的用户ID embedding,可以捕捉到用户的最新的兴趣点,对推荐很有帮助。
发布用户ID embedding这个过程会有延迟,在我们小红书刚上线online learning的时候,这个过程会有小时级的延迟,通过对系统做优化,延迟可以降低到几十分钟甚至更短。也就是说用户在小红书上产生行为几十分钟之后,他的用户向量就会被更新,他再次刷新小红书的时候,双塔模型会考虑到他最新的兴趣。
在我们小红书模型既要做全量更新,也要做增量更新,我画个图演示一下,这些是前天一天积累的数据,到了昨天凌晨的时候,我们把前天的数据打包成TFRecord文件。要基于前天凌晨全量训练出来的模型做训练,也就是说昨天凌晨模型初始化的时候,参数用的是前天凌晨全量训练出的模型,而不是随机初始化。然后我们拿前天积累的数据来训练模型,要把前天的数据做random shuffle打乱,然后做随机梯度下降,只训练one epoch,也就是说每条数据只过一遍。接下来是要基于这个全量训练出来的模型,做分钟级别的增量更新,从昨天凌晨到今天凌晨,不停做online learning,每隔几十分钟发布一次模型,刷新线上的用户塔embedding层参数。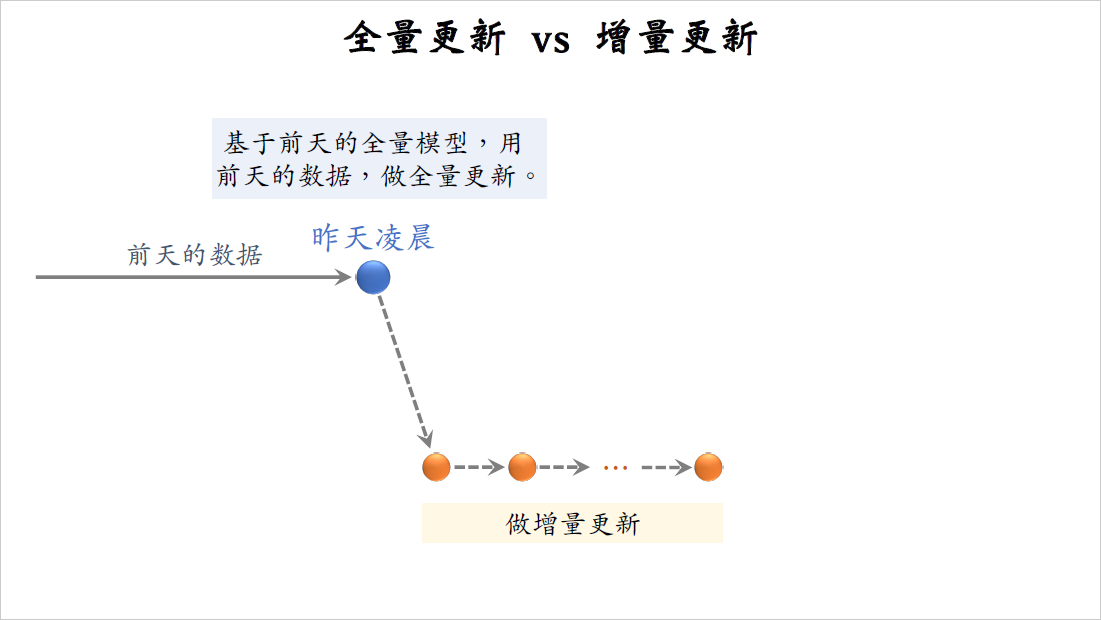
在昨天我们又积累了一天的数据,到了今天凌晨又该做一次全量更新。今天凌晨的全量更新,是基于昨天凌晨全量训练出来的模型,而不是用下面增量训练出来的模型,在完成这次全量训练之后,下面增量训练出的模型就可以扔掉了。然后再基于今天凌晨全量训练出来的模型,做分钟级别的增量更新,从今天凌晨到明天凌晨,不停做online learning,每隔几十分钟发布一次模型。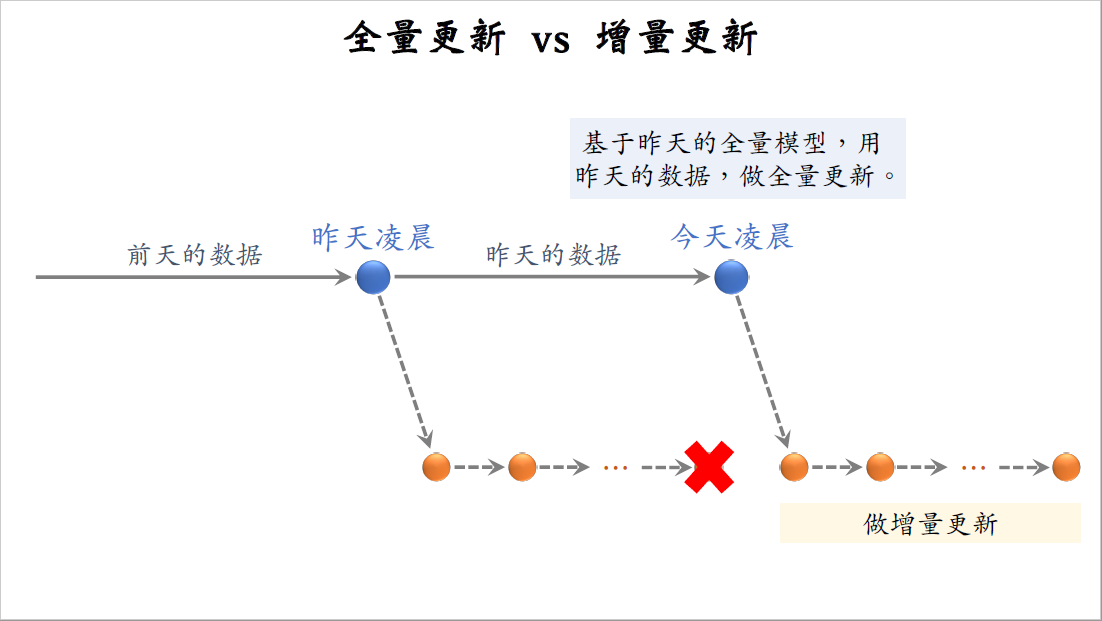
大家思考一个问题,能不能只做增量更新,不做全量更新呢。什么意思呢,就是去掉上面的全量更新,接着昨天的增量更新训练,继续把增量更新给做下去。这样只做增量更新,当然比既要做增量,也要做全量简单,工程实现会更容易训练,消耗的机器资源也更少,我们同时把两种都试过,发现只做增量的话效果不好,最好还是既要做全量,也要做增量。
为什么只做增量更新,效果不好呢?如果你只看一个小时的数据,它是有偏的,它的统计值跟全天的数据差别很大。为什么有偏呢?在不同的时间段,用户的行为是不一样的,比如中午和傍晚的数据明显会不一致,如果你只看5分钟的数据,那么偏差就更大了,它跟全天数据的统计值差别巨大。我们做全量训练的时候,要随机排列数据,也就是random shuffle,这样就是为了消除偏差。全量更新是在random shuffle过的数据上做,而增量更新,是按照从早到晚的顺序做训练。
同样是用一天的数据,这两种排列数据的方式,会导致训练的效果有差别,把数据按照从早到晚的时间顺序排列,效果不如把数据随机打乱,所以全量训练的效果比增量训练更好。
这就是为什么我们既要做增量训练,也要做全量训练。全量训练的模型更好,而增量训练可以实时捕捉用户的兴趣。
总结
这三节课详细讲解了双塔模型,最后总结一下。
双塔模型,顾名思义,有两个塔,一个用户塔,一个物品塔。两个塔各输出一个向量,两个向量的余弦值就是对兴趣的预估,这个值越大,用户就越有可能对物品感兴趣。
前面的课介绍了三种训练双塔模型的方式,分别是pointwise、pairwise、listwise。做训练的时候要用到正负样本,正样本是用户点击过的物品,负样本稍微复杂一些,简单负样本是全体物品,是从全体物品中做随机抽样,困难负样本是被排序淘汰的物品。
做完训练,把物品塔输出的物品向量存储到向量数据库里面,供线上做最近邻查找用。做线上召回的时候,拿到用户ID和用户画像,调用训练好的用户塔神经网络现算用户的向量$a$,然后把用户向量$a$作为query,查询物品的向量数据库,找到预先相似度最大的k个物品向量,返回这k个物品ID作为召回结果。
模型需要定期做全量更新和实时做增量更新。全量更新,意思是在今天凌晨,用昨天的数据训练整个神经网络做one epoch,随机梯度下降,也就是每条数据只用一遍。增量更新,意思是用最近产生的数据训练神经网络,训练的时候只更新ID embedding层,锁住全连接层不更新。
现在先进的推荐系统,都会结合全量更新和增量更新,每天做全量更新,实时做增量更新,每隔几十分钟要发布最近的用户ID embedding,供用户塔在线上计算用户向量,用这样的好处是可以捕捉到用户最新的兴趣点。