
召回10:地理位置召回、作者召回、缓存召回
本博文引自王树森老师推荐系统。
视频地址:召回10:地理位置召回、作者召回、缓存召回_哔哩哔哩_bilibili
课件地址: https://github.com/wangshusen/RecommenderSystem
前面几节课讲解了几种最重要的召回通道,这节课简单介绍我们小红书用到的其他几种召回通道,这几条召回通道很有用,但是重要性不高。
地理位置召回
GeoHash召回
有一类是根据用户所在的地理位置做召回。
GeoHash召回属于地理位置召回。之所以用这条召回通道,是因为用户对自己附近的人和事感兴趣,推荐系统应该出一些用户附近的内容。
系统维护一个地理位置GeoHash索引。GeoHash,意思是把经纬度编码成二进制哈希码方便检索,如果你不懂GeoHash的话,可以去搜一搜,网上有很多讲解,这里你就当GeoHash表示地图上一个长方形的区域。
索引是这样的,从GeoHash到优质笔记列表,也就是说以GeoHash作为索引,记录地图上一个长方形区域内的优质笔记笔记列表,按照时间顺序倒排,最新的笔记排在最前面。做召回的时候,给定用户的GeoHash,会取回这个区域内比较新的一些优质笔记。这条召回通道没有个性化召回纯粹只看地理位置,每次召回本地的一批优质笔记,完全不考虑用户兴趣。就是因为没有个性化,我们才得用优质笔记,笔记本身质量好,即使没有个性化,用户也很有可能会喜欢看,反过来既没有个性化,也不是优质笔记,那么召回的笔记大概率通不过粗排和精排。
看一下GeoHash索引的示意图,圈出来的是GeoHash,每个GeoHash都表示地图上一个长方形的区域,每个GeoHash后面都有一个笔记列表,意思是定位在这个地理位置的优质笔记,这个列表包含k篇优质笔记,排在最前面的是最新的笔记。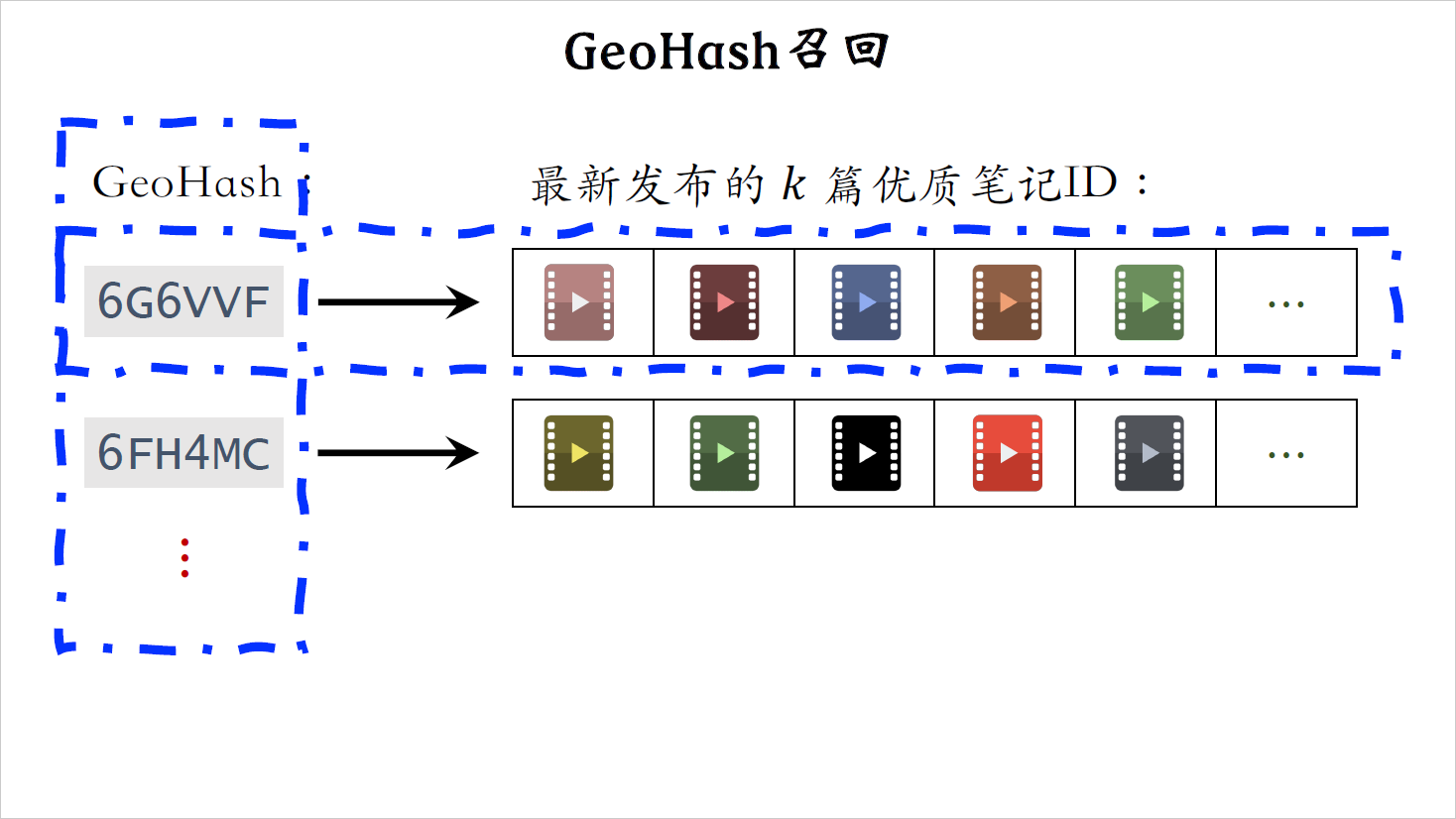
GeoHash召回很简单,如果用户允许小红书app获取用户定位,那么就根据用户定位的GeoHash,取回该地点最新发布的k篇笔记,至于这些笔记当中有哪些符合用户的兴趣呢,会留待排序模型决定。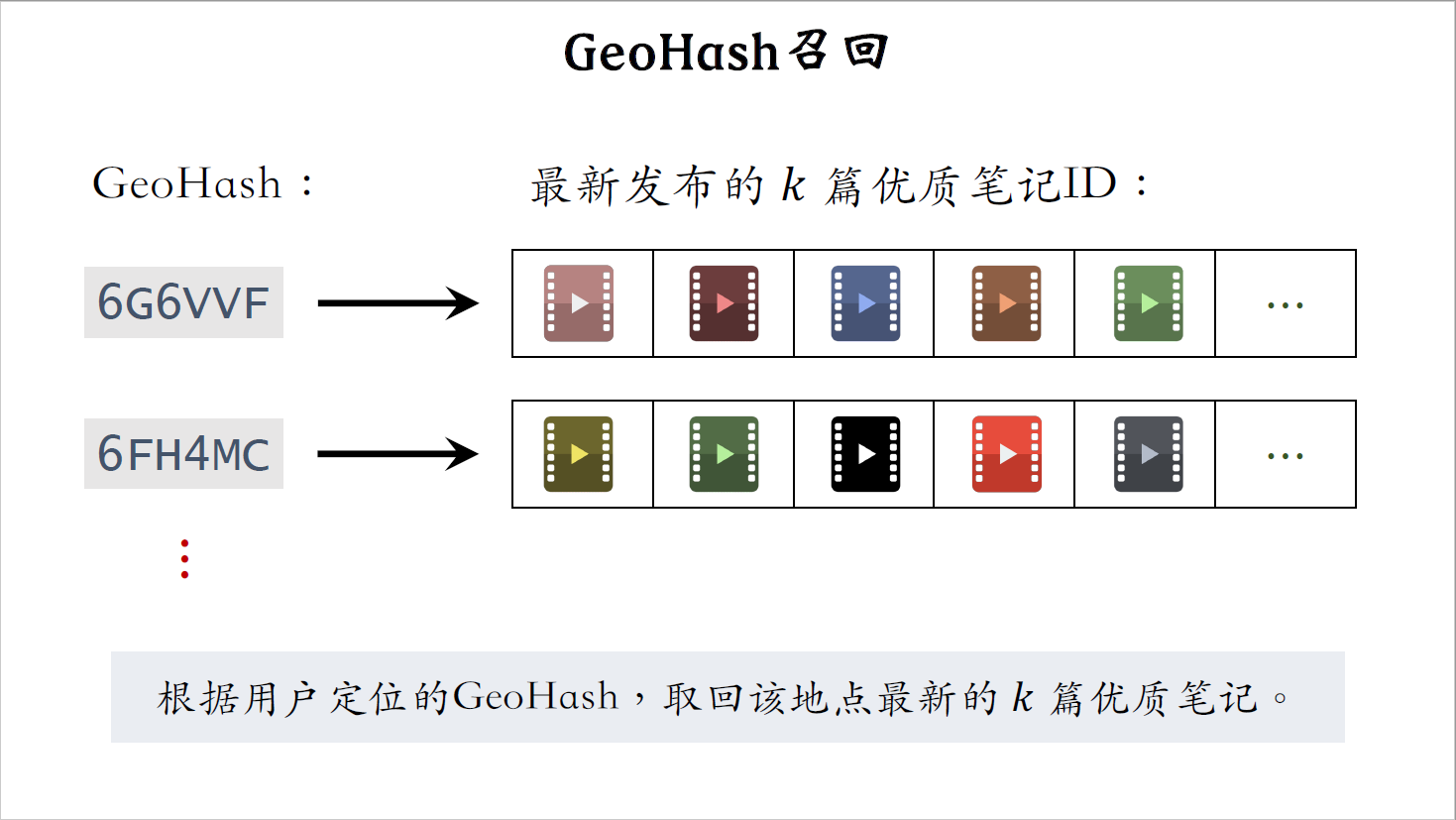
同城召回
刚才介绍了,GeoHash召回原理是用户对自己身边发生的事感兴趣,同城召回的原理是一样的,唯一的区别就是用城市作为索引,做召回的时候,根据用户所在的城市和曾经生活过的城市做召回,这条召回通道也没有个性化。
作者召回
关注作者召回
前面讨论了地理位置召回,下面讨论作者召回,意思是如果你对一个作者感兴趣,系统就会给你推这个作者发布的新笔记。
带社交属性的推荐系统都会有关注作者这样一个召回通道,假如我在小红书上关注老梁,以后推荐系统就会时不时的给我推送老梁发布的视频,尤其是在有新视频发布的时候。
系统维护两个索引,一个是用户到关注的作者,另一个是作者到发布的笔记,笔记的列表是按照时间顺序倒排的,也就是说新发布的笔记排在最前面。
现场做召回的时候,给定用户ID找到他关注的所有作者,再取回每个作者最新发布的笔记,这样就得到了一批笔记。
有交互的作者召回
一种类似的召回通道是有交互的作者召回,原理是这样的:如果用户给一篇笔记点赞,收藏或者转发,说明用户对该作者的笔记感兴趣。举个例子,我在小红书上碰巧看到玉石加工的视频,我觉得很有意思,我看完了还点个赞,我没有买玉石或者收藏玉石的打算,所以我不会关注这些作者,但给我推送这些作者新发布的玉石雕刻的视频,我很有可能会看完,所以即使我不关注作者,也应该继续给我推送他的视频。
系统维护的索引是从用户ID到有交互的作者列表,作者列表需要定期更新,最简单的策略就是保留最近交互的作者,删除一段时间没有交互的作者。在线上做召回的时候,要用到索引,给定用户ID,用索引找到有交互的作者,然后召回每个作者最新的笔记,这样就得到很多篇笔记。
相似作者召回
另一条召回通道是相似作者召回,想法是如果用户喜欢某位作者,那么用户可能会喜欢相似的作者,系统需要维护一个从作者到相似作者的作用。
作者相似性的计算类似于ItemCF,如果两个作者的粉丝有很大的重合,那么就判定两个作者相似。
线上做召回的时候,给定用户ID,找到他感兴趣的作者,感兴趣的作者包括用户关注的作者,以及用户有交互的作者。利用索引找到每个作者相似的一批作者,最后取回每个作者最新的一篇笔记,这样就召回了很多篇笔记。假设记录每个用户感兴趣的n个作者,每个作者有k个相似作者,那么一共有n×k个相似作者,取回每个作者最新的一篇笔记,那么一共召回了n×k篇笔记。
缓存召回
最后我介绍缓存召回,缓存召回的基本想法是复用之前n次推荐系统精排的结果。
背景是这样的:在我们小红书,精排输出几百篇笔记,送入重排;重排做多样性的随机抽样,比如用DPP从几百篇笔记中选出几十篇曝光给用户,也就是说精排的结果有一大半没有曝光,被浪费掉。这很可惜,好不容易走完召回粗排精排流程,只是碰巧随机抽样没有抽到,所以没有被曝光,应该想办法把这些笔记重新利用起来。
我们小红书大致是这样做的,按照精排的分数做排序,排到前50,但是没有曝光给用户的,不要浪费掉,而是缓存起来作为一条召回通道,下次用户刷小红书的时候,把缓存里的笔记取出来,作为一路召回的结果,精排排到前50的都是用户非常感兴趣的笔记,值得再次尝试。
这种缓存召回有个问题,缓存大小是固定的,比如最多存100篇笔记,每次就召回这100篇笔记。由于缓存大小固定,那么就需要退场机制,确保缓存里最多有100篇笔记。
有很多条规则作为退场机制,比如一旦笔记成功曝光给用户,那么就要从缓存中退场;如果超出了缓存大小,就移除掉最先进入缓存的笔记;每篇笔记最多被召回十次,达到十次就退场;每篇笔记最多保存三天,时间达到三天就退场。
这些都是最简单粗暴的规则,在这些规则的基础上,还能再细化规则,举个例子,假如想要扶持曝光比较低的笔记,那么可以根据笔记的曝光次数来设置规则,让低曝光的笔记在缓存里存更长的时间。
总结
最后总结一下这节课的内容,这节课介绍了三大类,一共六条召回通道,这些都是工业界实际在用的,只不过它的重要性比不上item cf swing双塔那些召回通道.
地理位置召回,包括GeoHash召回和同城召回,之所以用这种召回通道,是因为用户对自己附近的人和事感兴趣。
我介绍了三条作者召回通道,包括关注的作者,有交互的作者,还有相似的作者,我们把这些作者创作的内容推荐给用户。
最后我讲了缓存召回,意思是把精排中排名高,但是没有成功曝光的笔记缓存起来,再多尝试几次。