
排序01:多目标模型
本博文引自王树森老师推荐系统。
视频地址:排序01:多目标模型_哔哩哔哩_bilibili
课件地址: https://github.com/wangshusen/RecommenderSystem
前面的课程讲了召回下一个主题是排序,这节课先介绍最基础的多目标排序模型。
推荐系统的链路
我们先回顾一下推荐系统的链路,整条链路分为召回、粗排、精排、重排。
链路上的第一环是召回,有很多条召回通道,从几亿篇笔记中选出几千篇。
做完召回之后,要从中选出用户最感兴趣的,这就要用到粗排和精排。
粗排给召回的笔记逐一打分,保留分数最高的几百篇。
然后用精排模型给粗排选中的几百篇笔记打分,然后不做截断,让几百篇笔记全都带着精排分数进入重排。
最后一步是重排做多样性抽样,并且把相似内容打散,最终有几十篇笔记被选中展示给用户。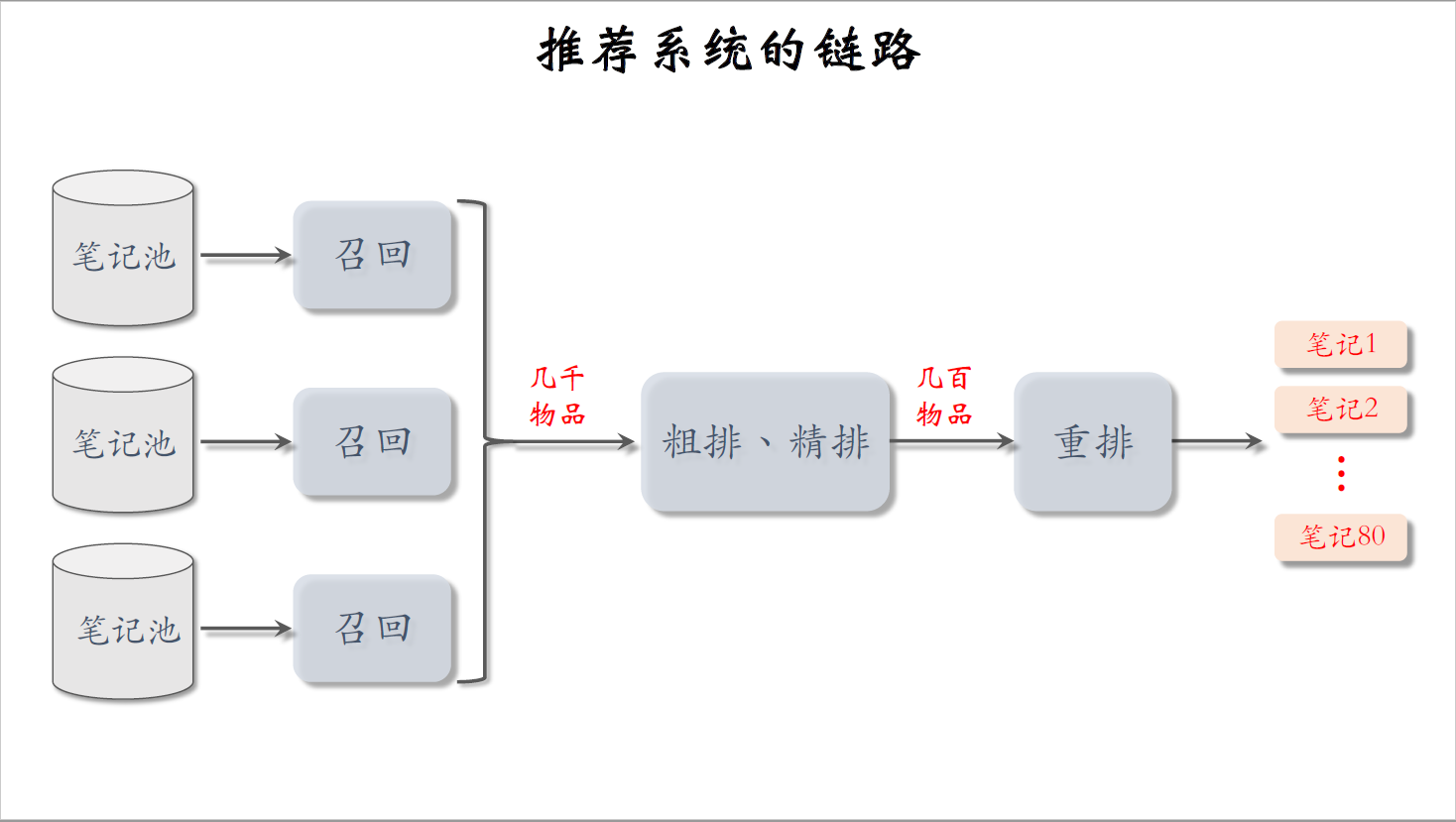
这节课后面几节课主要研究粗排和精排,它们的原理基本相同,只是粗排模型小,特征少,效果差一些。粗排的目的是做快速的初步筛选,如果不用粗排,直接把很大的精排模型用在几千篇候选笔记上,计算代价承受不住。粗排和精排的原理差不多,所以我讲解排序的时候就先不区分粗排和精排了。
用户笔记的交互
以小红书为例,排序的主要依据是用户对笔记的兴趣。兴趣可以反映在用户与笔记的交互上,对于每篇笔记系统会记录下面这些统计量:
- 曝光次数(number of impressions)就是一篇笔记被展示给多少用户,展示之后才会有点击等行为;
- 点击次数(number of clicks)就是一篇笔记被多少用户点开;
- 除此之外,还有点赞次数,(number of likes);
- 收藏字数(number of collects);
- 转发字数(number of shares)。
如果不理解我在说什么,建议先看一下第一节课。
可以用点击率之类的消费指标衡量一篇笔记受欢迎的程度。
点击率等于点击次数除以曝光次数,差不多有百分之一二十。
用户点开笔记之后,才会发生点赞,收藏,转发等行为。点赞率等于点赞次数除以点击次数,注意这里的分母是点击次数,而不是曝光次数。
收藏率的定义是类似的,收藏率等于收藏次数除以点击次数。
转发率等于转发次数除以点击次数,转发是很少见的行为,远少于点赞和收藏,但是转发很重要。转发到微信之类的平台,可以给小红书吸引到外部的流量。
排序的依据
推荐系统召回几千篇笔记,然后做排序,从召回的笔记中选出几十篇展示给用户,那么排序的依据是什么呢?
在把笔记展示给用户之前,我们要事先预估用户对笔记的兴趣,一些都使用机器学习的方法,对点击率,点赞率,收藏率,转发率之类的指标做预估。
做完预估之后,要对这些分数做融合,最简单的融合公式就是加权和,比如点击率的权重是一,点赞率、收藏率、转发率之类的权重都是二。权重是做AB测试调出来的。当然有很多比加权平均更好的融合公式,后面我们会讲。
最后,按照融合的分数给笔记做排序和截断,保留分数最高的笔记,淘汰分数低的笔记。
多目标模型
模型
下面我要讲解排序用的多目标模型。
现在工业界基本上都用这种模型,当然会在这个基础上做很多改进。
排序模型的输入是各种各样的特征,把能用到的特征都用到了。
- 用户特征主要是用户ID和用户画像。
- 物品特征包括物品ID,物品画像,还有作者信息。
- 统计特征包括用户统计特征和物品统计特征。比如,用户在过去30天中一共曝光了多少篇笔记,点击了多少篇笔记,点赞了多少篇笔记。再比如,候选物品在过去30天中一共获得多少次曝光机会?获得了多少次点击点赞?
- 场景特征是随着用户请求传过来的,包含当前的时间,用户所在的地点。
这些信息对推荐很有用。比方说候选物品跟用户如果在同一个城市,那么用户对物品会有更高的兴趣。再比如,当前是否是周末,节假日也会影响用户的兴趣?把这些特征做concatenation输入神经网络。神经网络可以是简单的全连接网络,可以是wide and deep,也可以是更复杂的结构。
神经网络会输出一个向量。这个向量再输入四个神经网络,每个神经网络有两到三个全连接层,最后一个激活函数是sigmoid。
四个神经网络分别输出点击率,点赞率,收藏率,转发率的预估值。四个预估值都是实数,介于零到一之间。
推荐系统排序就主要靠这四个预估值,它们反映出用户对物品的兴趣。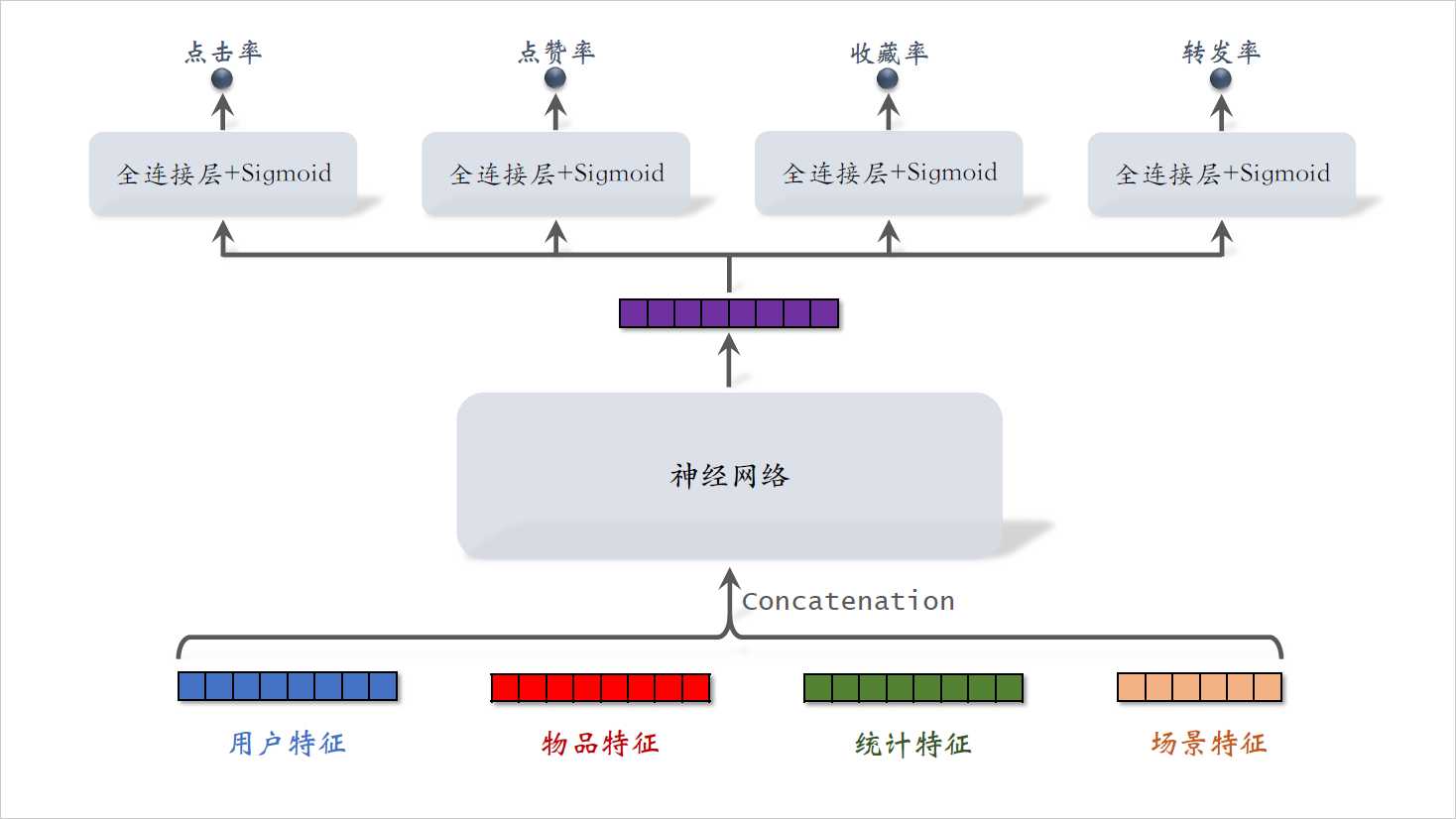
训练
接下来我要讲模型的训练。把模型输出的点击率、点赞率、收藏率、转发率分别记作$p_1$、$p_2$、$p_3$、$p_4$,它们都是模型做出的预估。做训练的时候,我们要让这些预估值去拟合真实的目标。
把真实的目标记作$y_1$到$y_4$,分别对应点击,点赞,收藏,转发的行为。$y$要么是零,要么是一。
举个例子,四个数分别是1、0、0、1,意思是用户对物品有点击,没点赞,没收藏,有转发。这些是用户真实的行为,被系统记录下来。
我们要用这样的数据来训练模型。训练是要鼓励模型的预测接近目标。其实就是二元分类,比如判定用户是否会点击物品。有点击、点赞、收藏、转发这四个任务,每个任务都是一个二元分类。
既然是二元分类,我们就用交叉熵损失函数。对于点击这个任务,我们用$y_1$和$p_1$的交叉熵作为损失函数。$p_1$越接近$y_1$,那么损失函数就越小。我们把四个损失函数的加权和作为总的损失函数。权重$\alpha$是根据经验设置的。在收集的历史数据上训练神经网络的参数,最小化损失函数。损失函数越小,说明模型的预测越接近真实目标。做训练的时候把损失函数关于神经网络的参数求梯度做梯度下降,更新神经网络的参数。
实际的训练中会有很多困难,我重点讲其中一个。
做训练的时候存在类别不平衡的问题,正样本少,负样本多。比方说每给用户曝光100篇笔记,用户点击10篇,其他90篇没有点击,有点击的是正样本,没有点击的是负样本。用户点开100篇笔记之后,转发其中的十篇,其余90篇没有转发。转发的是正样本,没有转发的是负样本,正负样本的数量非常不平衡。要太多的负样本,用途不大,白白浪费计算资源。解决方案就是负样本的随机降采样(down sampling)。负样本过多,所以我们不用全部的负样本,只用其中一小部分负样本,这样的话正负样本的数量会稍微平衡一些。这样可以减少样本数量,降低训练的计算代价。比方说,原本一天积累的数据需要在集群上训练十个小时,做降采样之后,负样本的数量减小了很多,那么训练只需要三个小时。
预估值校准
给定用户特征和物品特征,用神经网络预估出点击率,点赞率等分数之后,再对这些预估分数做校准。做完校准之后,才能把预估值用于排序。
首先解释一下为什么要做校准。设正样本和负样本的数量分别是$n_+$和$n_-$。以点击为例,曝光之后有点击就是个正样本,否则就是负样本。负样本数量通常远大于正样本。在训练的时候会对负样本做降采样,抛弃一部分负样本。这样会让正负样本的差距不太悬殊。
把采样率记作$\alpha$,它介于零到一之间。使用的负样本的数量等于$\alpha·n_-$。由于减少了负样本数量,模型预估的点击率会大于真实点击率。$\alpha$越小,负样本越少,模型对点击率的高估就会越严重。
下面我要推导校准公式对预估的点击率做校准。把真实的点击率记作$p_{true}$,它的期望等于正样本数量$n_+$除以样本总数。样本总数等于$n_++n_-$。预估的点击率叫做$p_{predict}$,它的期望等于正样本数量$n_+$除以训练用的样本总数,也就是公式中的分母$n_+ + \alpha · n_-$。$\alpha$是采样率,用来减少负样本数量。
把上面两个公式结合起来,消掉$n_+$和$n_-$,得到了下面的公式,这个公式就是对预估点击率的校准。等式左边的$p_true$表示校准之后的点击率。等式右边是对预估点击率$p_{predict}$做的变换,公式中用到了采样率$\alpha$。
在线上做排序的时候,首先让模型预估点击率$p_{predict}$,然后我们用这个公式做校准。最后拿校准之后的点击率作为排序的依据。
这节课介绍了排序的多目标模型,用于估计点击率,点赞率等指标。做完预估之后,要根据负采样率对预估值做校准。相信大家已经理解了多目标模型以及预估值的校准公式。这节课就讲到这里,感谢大家观看。