
排序05:排序模型的特征
前面的课程讲解了排序模型的结构,这节课内容是排序模型用的特征。
用户画像
召回和排序的模型中都有用户属性,用户属性记录在用户画像中。
用户ID是排序中最重要的特征之一,用户ID本身不携带任何有用的信息,但是模型渠道的ID embedding向量对召回要排序模型有很重要的影响。召回和排序都会对用户ID做embedding,通常用32位或者64位向量。
人口统计学属性包括性别,年龄等等,不同性别,不同年龄段的用户兴趣点差别很大。
用户的账号信息包括用户注册时间,活跃度新用户和老用户,高活低活用户的行为区别很大,模型需要专门针对新用户,低活用户做优化。
再就是用户感兴趣的类目、关键词、品牌,这些信息可以是用户自己填写的,也可以是算法自动提取的,这些用户兴趣的信息对排序也是很有用的。
物品画像
与用户画像相对的是物品画像,现在几乎所有的工业界推荐系统中都会使用用户画像和物品画像。
物品ID的重要性自然不用说,物品ID embedding在召回和排序中的重要性非常高。
物品的发布时间或者物品年龄也是非常重要的特征。在小红书一篇笔记发表的时间越久,价值就越低,尤其是明星出轨、电商打折之类的强时效性话题热度只有几天时间。
笔记定位的Geohash和所在城市都对召回和排序有用。Geohash是对经纬度的编码,表示地图上一个长方形的区域。
再就是笔记的内容,包括标题、类目、关键词、品牌等信息,通常对这些离散的内容特征做embedding变成向量。
笔记字数,图片数,视频清晰度,标签数,这些都是笔记自带的属性,这些属性反映出笔记的质量。笔记的点击和交互指标,跟这些属性相关。
内容信息量,图片美学是算法打的分数,事先用人工标注的数据训练cv和nlp模型,当新笔记发布的时候,用模型给笔记打分,把内容信息量,图片美学这些分数写到物品画像中。这些分数可以作为排序模型的特征。
用户统计特征
除了用户画像和物品画像,排序模型还会用到用户统计特征和笔记统计特征。
比如系统会记录用户最近30天的点击率,点赞率,收藏率,转发率,这类统计值。类似的,还会记录最近七天的,一天的,一小时的,用各种时间力度可以反映出用户的实时兴趣,短期兴趣,还有中长期兴趣。
除此之外,还要分桶统计各种指标,比如小红书的笔记可以分为图文笔记和视频笔记这两类,对两类笔记分开做统计,比如最近七天该用户对图文笔记的点击率,对视频笔记的点击率。对图文和视频分别做统计,可以反映出用户对两类笔记的偏好。
类似的还会按照笔记类目做分桶,比如最近30天用户对美妆笔记的点击率,对美食笔记的点击率,对科技数码笔记的点击率,这些统计量可以反映出用户对哪些类目更感兴趣,如果一个用户对美食笔记的点击数,点击率等指标都偏高,说明这个用户对美食类目感兴趣。
笔记统计特征
刚才讨论了用户的统计特征,下面看一下笔记的统计特征。
跟用户特征类似,系统会记录每篇笔记最近的曝光数,点击数,点赞数,收藏数等指标,时间力度有30天,七天,一天,一小时,这些统计量反映出笔记的受欢迎程度。如果点击率,点赞率等指标都很高,说明笔记质量高,算法应该给这样的笔记更多的流量。使用不同的时间力度也是有道理的,有些笔记的时效性强,30天指标很高,但是最近一天的指标很差,说明这样的笔记已经过时了,不应该给更多流量。
还会按照笔记的受众做分桶,比如把受众分成男女两个桶,分别计算男性的点击率和女性的点击率,这样的统计量可以反映出笔记是更受男性欢迎呢,还是更受女性欢迎。比如一篇笔记是对粉色键盘的测评,笔记的总体点击点赞指标都很高,但是来自男性用户的点击率很低,这说明不应该把这款粉色键盘推荐给男性用户。除了性别分桶,还有年龄分桶,地域分桶等等,用途也是类似的。
再就是作者的统计特征,比如作者发布的笔记数,作者的粉丝数,还有消费指标,包括曝光数,点击数,点赞数,收藏数等等。这些特征反映了作者的受欢迎程度,以及他作品的平均品质,很显然,如果一个作者已有作品的品质普遍很高,他新发布的作品的品质大概率也会很高。
场景特征
最后一类特征是场景特征,他们是随着推荐请求传来的,不用从用户画像,笔记画像的数据库中获取。
用户当前定位的经纬度,定位的城市属于场景特征。当用户登录小红书的时候,如果用户给小红书权限,允许使用用户的地理定位,那么小红书的服务器就会知道用户的经纬度和所在城市,这些信息对召回和排序都有用,因为用户可能对自己附近发生的事感兴趣。
当前的时刻也属于场景特征,对推荐很有用,一个人在同一天不同时刻的兴趣可能有所区别,在上班路上,在办公室或者晚上睡觉前,用户想看的东西可能不一样。
还有其他的场景特征,比如是否是周末,是否是节假日。周末和节假日的时候,用户可能对特定的话题感兴趣。
再就是设备信息,比如手机品牌,手机型号,操作系统。我也不知道为什么安卓用户和苹果用户的点击率,点赞率这些指标差异非常显著。所以设备信息也是有用的特征。
特征处理
最后简单讨论一下特征处理。
离散特征的处理很简单,就是做embedding。
离散特征有很多种,用户ID,笔记ID,作者ID的数量都非常巨大,都是几千万几亿的级别,消耗内存很大,像类目,关键词,城市,手机品牌这样的离散特征处理起来很容易,比方说笔记的类目也就几百个,关键词也就几百万个,给他们做embedding比较容易,消耗内存不多。
连续特征有不同的处理方法,第一种方法是做分桶,把连续特征变成离散特征。像年龄,笔记字数,视频长度之类的连续特征都可以这么处理,比方说把连续的年龄变成十个年龄段,做one-hot编码或者做embedding。
连续特征,还有其他不同的处理方式。曝光数,点击数,点赞数,这些指标都是长尾分布,以曝光数为例,大多数笔记只有几百次曝光,而已,而极少数的笔记能有上百万次曝光。假如直接把曝光数作为特征输入模型,一旦出现几十万,几百万这种特别大的数值计算会出现异常,比如训练的时候梯度会很离谱,做推理的时候预估值会很奇怪,对这样的连续特征通常是做$log(1+x)$变换,这样会解决异常值的问题。
除此之外,还可以把曝光数,点击数,点赞数这样的指标变成点击率,点赞率,这里还需要做一下平滑,去掉偶然性造成的波动。
在我们实际的推荐系统中,两种变换之后的连续特征都作为模型的输入,比如$\log(1+曝光数)$,$\log(1+点击数)$会被用到,平滑之后的点击率,点赞率也会被用到。
特征覆盖率
前面我逐一解释了为什么这些特征有用,在做特征工程的时候,需要关注一下特征覆盖率。
在理想的情况下,每个特征都能覆盖百分之百的样本,也就是说不存在特征缺失的问题,但实际上大多数特征都有缺失,覆盖率达不到百分之百。
比如很多用户注册的时候不填写年龄,所以用户年龄特征的覆盖率远小于百分之百。
再比如很多用户设置了隐私权限,使得app不能获得用户的地理定位,因此场景特征有缺失。
做特征工程的时候,要分析特征的覆盖率,可以想各种办法提高特征覆盖率。如果一个特征很重要,提高它的覆盖率,肯定可以显著提升模型的表现。除了特征覆盖率,做特征工程的时候,还要考虑一下当特征缺失的时候,要用什么作为默认值。
数据服务
推荐系统用到三个数据源,包括用户画像,物品画像,还有统计数据。三个数据源都存储在内存数据库中,在线上服务的时候,排序服务器会从三个数据源取回所需的数据,然后把读取的数据做处理,作为特征喂给模型,模型就能预估出点击率,点赞率等指标。
最后我粗略介绍一下线上服务的系统架构,我做了很多简化,实际上的系统会比我讲的要复杂很多。
当用户刷小红书的时候,用户请求会被发送到推荐系统的主服务器上。主服务器会把请求发送到召回服务器上,做完召回之后,召回服务器会把几十路召回的结果做归并,把几千篇笔记的ID返回给主服务器。召回需要调用用户画像,这里我就不展开讲了,我们把重点放在排序上。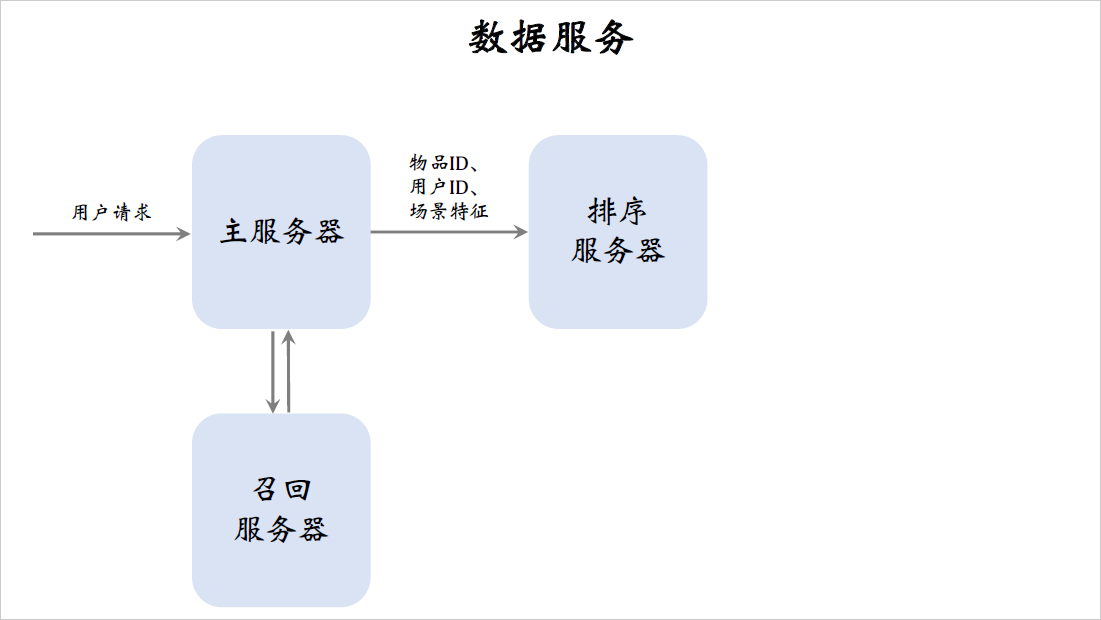
主服务器把笔记ID,用户ID还有场景特征发送给排序服务器,这里有一个用户ID和几千个笔记ID,笔记ID是召回的结果。用户ID和场景特征都是从用户请求中获取的,场景特征包括当前的时刻,用户所在的地点以及手机的型号和操作系统。
接下来排序服务器要从多个数据源中取回,排序所需的特征主要是这三个数据源:用户画像,物品画像还有统计数据。
取回的特征分别是用户特征,物品特征,统计特征。用户画像数据库线上压力比较小,因为每次只读一个用户的特征,而物品画像数据库压力非常大,粗排要给几千篇笔记做排序,读取几千篇笔记的特征。
同样的道理,存用户统计值的数据库压力小,存物品统计值的数据库压力很大,在工程实现的时候,用户画像里面存什么都可以,特征可以很多很大,但尽量不要往物品画像里塞很大的向量,否则物品画像会承受过大的压力。
用户画像较为静态,像性别年龄这样的属性几乎不会发生变化,用户活跃度,兴趣标签这些属性通常也就是天级别的刷新变化很慢。物品画像的变化更少,可以认为是完全静态的,物品自身的属性,还有算法给物品打的标签,在很长一段时间内不会发生任何变化。
对于用户画像和物品画像,最重要的是读取速度快,而不太需要考虑时效性,因为他们都是静态的。有时候甚至可以把用户画像和物品画像缓存在排序服务器本地,让读取变得更快。但是不能把统计数据在本地缓存,统计数据是动态变化的,时效性很强,比如用户刷新小红书往下刷了30篇笔记,点击了五篇,点赞了一篇,那么这个用户的曝光点击点赞的统计量都发生了变化,要尽快刷新数据库。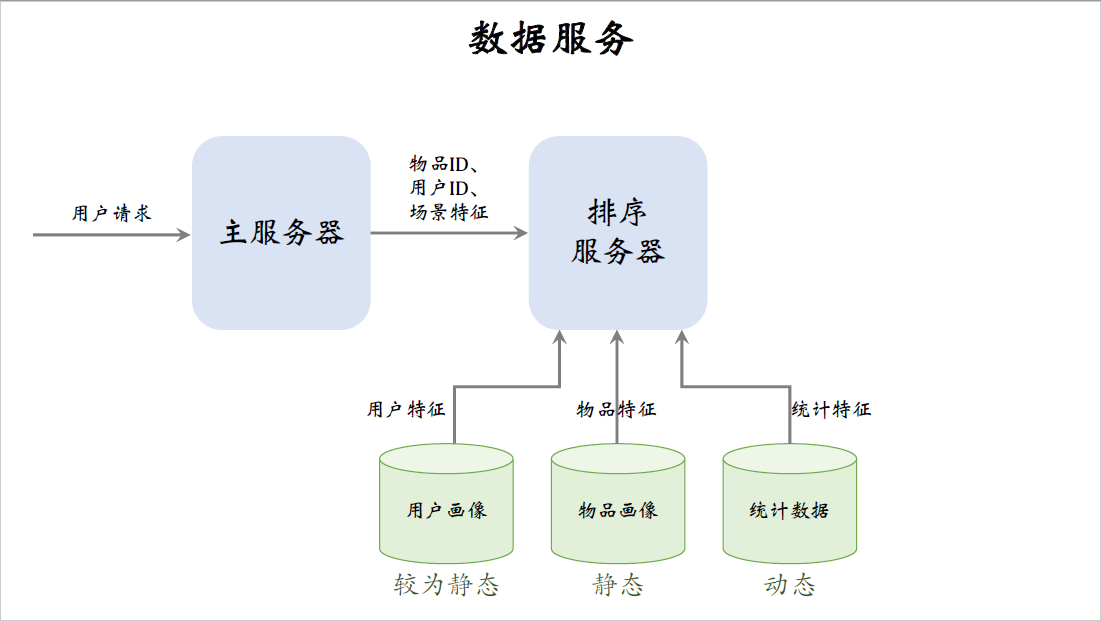
在收集到排序所需的特征之后,排序服务器把特征打包传递给TF Serving。tensorflow会给笔记打分,把分数返回给排序服务器,排序服务器会用融合的分数,多样性分数,还有业务规则给笔记做排序,把排名最高的几十篇笔记返回给主服务器,这些就是最终给用户曝光的笔记。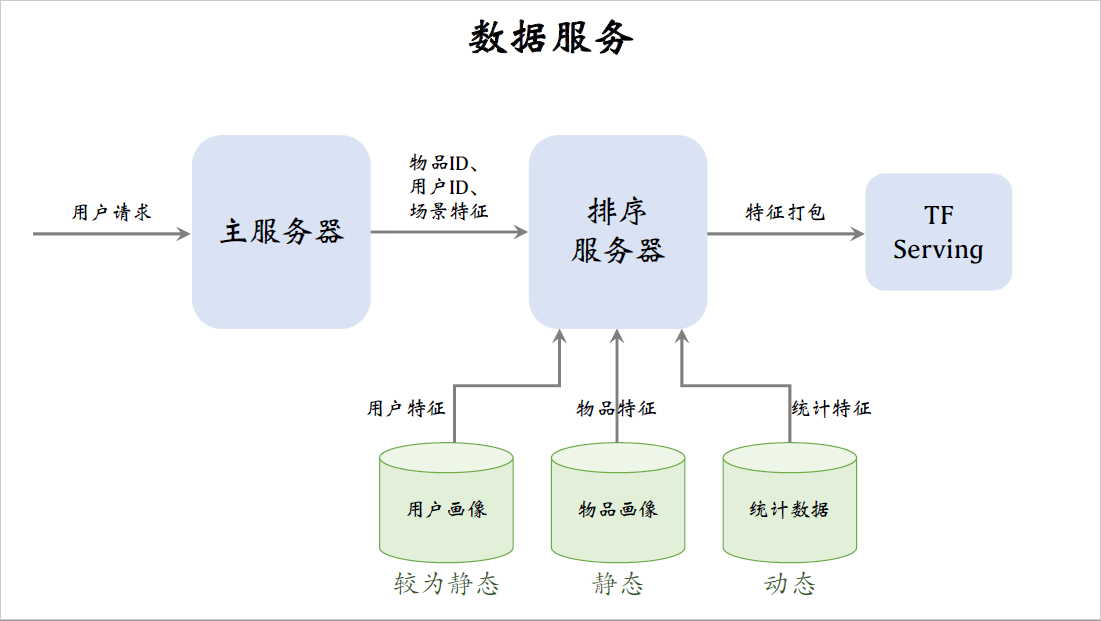
这节课讲了排序所需的特征,包括用户画像,物品画像统计特征,还有场景特征,工业界基本上都是这么做的,只在特征的选择和处理上会贴近各自的业务场景,这节课就讲到这里,感谢大家观看。